Parallel Machine Models¶
For Students
You are likely reading this for an algorithms or data structures course, or perhaps some other course for a computer science (CS) major. Whether you choose to major in CS or are learning CS in the hopes of applying it to your chosen field, you should be aware that the time of parallel computing is now: all practitioners and theoreticians of computer science must be able to think in parallel when designing solutions to problems, because all computing platforms that we work on will be inherently parallel machines, in that they will contain multiple processing units capable of manipulating data simultaneously, i.e. in parallel. For this reason, in this unit we will begin discussing the process of thinking in parallel when considering how to design algorithms to solve particular problems. The first problem we will consider is one of the fundamental problems of computer science: that of sorting a set of N items, where N may be very large. Before looking at parallel algorithms to solve this problem, we must first have a clear idea of what types of parallel platforms there are in practice and how we can use an abstract theoretical parallel machine instead to make it easier for us to reason about the complexity and performance of parallel algorithms.
For Instructors
This module is designed to be used when students are studying ‘divide and conquer’ sorting algorithms. In particular, merge sort is used as an example. This could be expanded to include quicksort and parallel implementations of it, such as that suggested by Quinn.
Learning Objectives¶
Base Knowledge¶
- Students should be able to describe the PRAM model of computation and how it differs from the classical RAM model.
- Students should be able to describe the difference between the following memory access models associated with the PRAM model of computation: EREW, CREW, CRCW.
- Students should be able to describe the difference between shred memory and distributed memory machine models.
- Students should be able to visualize and describe these simple forms of communication interconnection between processors: linear array, mesh, binary tree.
Conceptual/applied knowledge¶
- Given a theoretical PRAM shared memory model, a particular memory access model, and an interconnection network, students should be able to:
- develop an algorithm for sorting a large collection of N data items,
- develop an algorithm for searching a large collection of N data items [optional, future]
- develop an algorithm for traversing a graph of size N [optional, future] and in all cases reason about the complexity of their solution.
Perquisites and Assumed Level¶
Before studying this material, students should be familiar with the sequential version of merge sort, or at least some other type of divide and conquer recursive algorithm. Students should also have an initial understanding of how to reason about time complexity of sorting algorithms in terms of the number of items being sorted. This reading assumes that the student may not be deeply familiar with computer organization and hardware yet, so these topics are approached in a relatively high-level, abstract way. Models of Parallel Computatio
Models of Parallel Computation¶
Types of parallel computers, or platforms¶
Until 2004, when the first dual core processors for entry-level computer systems were sold, all computers that most individuals used on a regular basis contained one central processing unit (CPU). These computers were classic von Neuman machines, where single instructions executed sequentially. Some of these instructions can read or write values to random access memory (RAM) connected to the CPU. These machines are said to follow the traditional RAM model of computation, where a single processor has read and write (RW) access to memory.
Today, even the next generation of netbooks and mobile phones, along with our current laptops and desktop machines, have dual core processors, containing two ‘cores’ capable of executing instructions on one CPU chip. High-end desktop workstations and servers now have chips with more cores (typicaly 4 or 8), which leads to the general term multicore to refer to these types of CPUs. This trend of increasing cores will continue for the foreseeable future- the era of single processors is gone.
In addition to the trend of individual machines containing multiple processing units, there is a growing trend towards harnessing the power of multiple machines together to solve ever larger computational and data processing problems. Since the early to mid 1980’s, many expensive computers containing multiple processors were built to solve the world’s most challenging computational problems. Since the mid-1990’s, people have built clusters of commodity PCs that are networked together and act as a single computer with multiple processors (which could be multicore themselves). This type of cluster of computers is often referred to as a beowulf cluster, for the first of these that was built and published. Major Internet software companies such as Google, Yahoo, and Microsoft now employ massive data centers containing thousands of computers to handle very large data processing tasks and search requests from millions of users. Portions of these data centers can now be rented out at reasonable prices from Amazon Web Services, making it possible for those of us who can write parallel programs to harness the power of computers in ‘the cloud’- out on the Internet away from our own physical location.
Thus, in fairly common use today we have these major classes of parallel computing platforms:
- multicore with shared memory,
- clusters of computers that can be used together, and
- large data centers in the cloud.
In addition, in the past there were many types of multiprocessor computers built for parallel processing. We draw on the research work conducted using these computers during the 1980’s and 1990’s to explain the following theoretical framework to describe models of parallel computing.
Theoretical Parallel Computing Models¶
The advent of these various types of computing platforms adds complexity to how we consider the operation of these machines. For simplicity, we will loosely use the term ‘processor’ in the following discussion to refer to each possible processing unit that can execute instructions in the three major types of platforms described above (you will likely see this term being used differently in future hardware design or operating systems courses). The memory might be shared by all processors, some of the processors, or none (each has its own assigned memory). Each processor may be capable of sending data to every other processor, but it may not. We need to define a framework to describe these various possibilities as different types of computing models. The type of computing model will dictate whether certain algorithms will be effective at speeding up an equivalent task on a single sequential RAM computer.
The PRAM Model¶
The sequential RAM computer with one processor differs from parallel computing platforms not only because there are multiple processing units, but also because they can vary in how available memory is accessed. When considering algorithms for parallel platforms, it is useful to consider an abstract, theoretically ideal computing model called a Parallel Random Access Machine, or PRAM. In such a machine, a single program runs on all processors, each of which has access to a main memory that is shared among them, as in Figure 1.
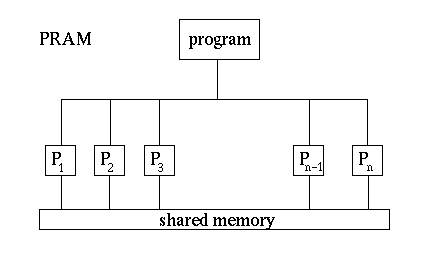
Figure 1. The PRAM model. (Image taken from http://www.mesham.com/article/Communication)
A PRAM machine with large numbers of processors has not been built in practice, but the model is useful when designing algorithms because we can reason about the complexity of those algorithms. The common multicore machines available today can be considered to be PRAM, but have a low number of processors (n in Figure 1). Note that the hardware involved to enable all processors to have access to memory is difficult to build so that it is fast, which is why we don’t yet have PRAM machines with many processors and large amounts of memory (This will be clearer when you’ve take a hardware design or computer organization course.)
Having many processing units, each running a program simultaneously, increases the complexity about how they coordinate to access memory. In this case, more than one processor may want to read from or write to the same memory location at the same time. In the theoretical PRAM model, it is useful for us to consider the following three possible strategies for handling these simultaneous attempts to access a data element in memory:
- Exclusive Read, Exclusive Write (EREW). Only one processor at a time can read a memory value and only one processor at a time can write a memory value.
- Concurrent Read, Exclusive Write (CREW). Many processors can read a data value at one time, but only one processor at a time can write a memory value.
- Concurrent Read, Concurrent Write (CRCW). Many processors can read a data value at one time, and many processors can write a data value at one time.
You may be wondering what we mean by a memory value. We could consider various granularities: it might be a whole array of data, such as integers, or it might be the individual integers themselves. In practice, this can vary for various types of hardware. For simplicity, we will assume that one memory value is one data value, such as an integer, a floating point number, or a character- these are what each processor can access.
With each of these memory access models, we also need to consider what order the reads and writes will occur in. As you consider parallel algorithms for various tasks, it may become necessary to reason about which process of the more than one that require access to a data item will be chosen to go first. You want avoid solutions where the order of reads and writes will make a difference in the final result, but it may become important to specify ordering.
- Concurrent Reads (CR)
- For concurrent reads (CR) between processors, all will get the same result and memory is not changed, so there is not a conflict at that single step that would cause your solution to be incorrect, unless you’ve devised an incorrect solution.
- Exclusive Write (EW)
- Exclusive write (EW) typically means that your code should be designed so that only one processor is writing a data value to one memory location at one execution step.
- Exclusive Read (ER)
- Exclusive read (ER) usually means that your code should be written such that only one processor reads a data value at one step.
Warning
For EW and ER, a runtime error in your code would result if more than one processor attempted to read or write to the same data value at a certain step.
- Concurrent Writes (CW)
- Concurrent writes could be handled in a variety of ways; one of the more common approaches is to state that a higher (or lower) processor number goes first, thus giving it priority. This concurrent write case is the hardest to design algorithms for. Luckily, it is not yet achieved in practice, so we won’t spend time considering it.
All of this discussion about the PRAM model of a parallel machine leads us to one more important point that you may be wondering about: when we have a program running on multiple processors, just which step is running on each processor at any point in time? As you might guess, the answer once again in practice depends on the type of machine. In the PRAM model we have two main types of program step execution on data:
- Multiple Instruction, Multiple Data (MIMD): each processor is stepping through the program instructions independently of the other processors, and each could be working on different data values.
- Single Instruction, Multiple Data (SIMD): each processor is on the same instruction at any time, but but each is working on a separate data value.
For the rest of this discussion, we will assume that our PRAM machine is a MIMD machine.
Stop and Consider this:
If we are assuming a SIMD PRAM machine, do we need to worry about which data access pattern (EREW, CREW, or CRCW) we have?
The distributed memory model¶
On the opposite extreme of the shared memory PRAM model is the the fully distributed model, as shown in Figure 2. Here each processor has its own memory, and must communicate with other processors to share data. Clusters and data centers fall into this category. One of the common types of program execution models for the distributed memory case is called Single Program, Multiple Data (SPMD). In SPMD, a program is written as a task to be executed on a portion of data, and each processor runs that program. The data each processor works on may be sent to it from another processor, or may reside on it already. At certain points in time, it may be necessary for the programs to synchronize and send each other data they have worked on.
Other hybrid parallel computer organizations have been built, in which processors have individual memory and a pool of shared memory.
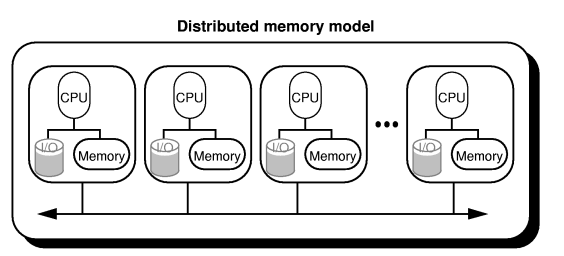
Figure 2 The fully distributed model. (Image take from http://www.mesham.com/article/Communication)
The range of parallel computing platforms leads to a wide range of different programming models that are suited to a particular platform. For the purposes of considering parallel algorithms and reasoning about their efficiency, however, it is useful to consider the theoretical PRAM model (MIMD assumed) with one of its 3 possible memory access strategies. Thus, we can design algorithms and have a sense for how they will perform, and in practice will implement them using various platforms and associated software.
Arrangement of Processors¶
To design a parallel algorithm, we will assume PRAM as our base model. We will design a possible parallel solution, often by considering an original sequential solution and looking for places where operations can be run in parallel. Then we will examine whether the algorithm follows EREW, CREW, or CRCW access to data. We may choose to fix the number of processors, n, or we might begin with the simplified case of assuming we have an infinite number of processors. It will also be useful to consider a possible pattern of communication among the processors, which we can visualize as placing them in a particular arrangement. The simplest arrangements are shown in Figure 3: a linear array (which can be extended to a ring by connecting P1 to Pn), a mesh, or a binary tree.
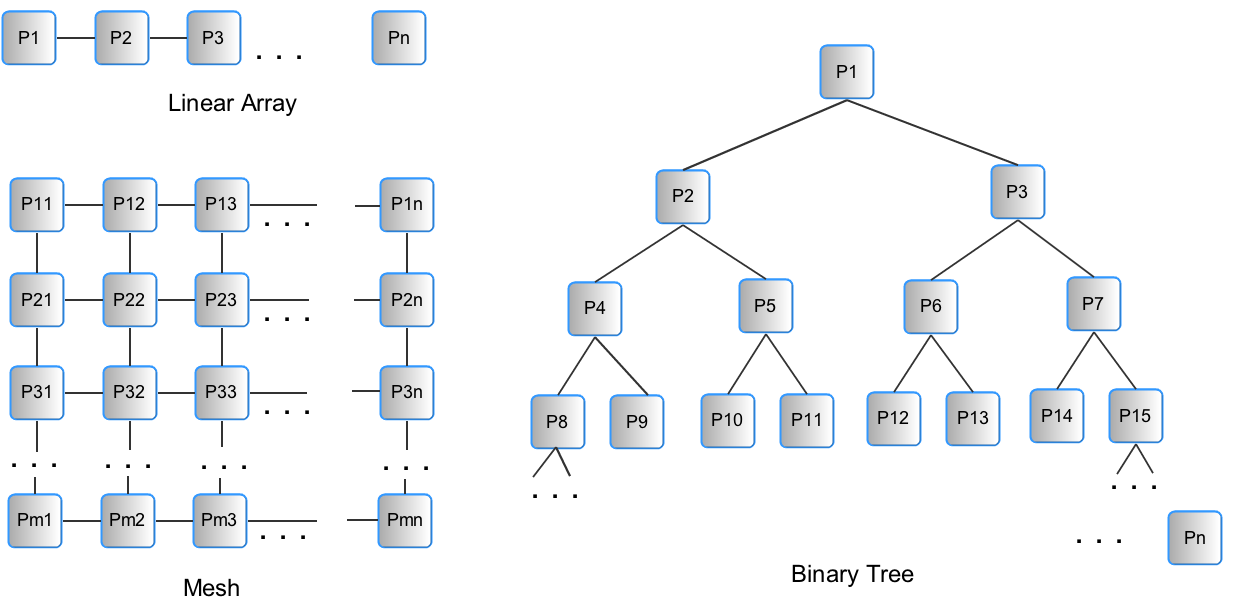
Figure 3 Simple, yet useful arrangements of processors to consider when designing parallel algorithms.
