Fun with key signatures¶
Let’s get our hands dirty by answering a practice question: What is the most common key signature in the dataset?
A key signature is made up by a key (C, G#, etc) and a mode, either major or minor (these aren’t the only modes, but they are the only ones in the dataset). Both the key and the mode are important, because A minor and C major contain the same notes so if our mode is incorrect we will get bad results.
Luckily the dataset provides us with a measure of how accurate it’s guesses for the key and the mode are. These are both floats from 0-1 so to find the confidence in the key signature we’ll multiply them, that way if the key is certain but the mode is totally unknown, the confidence will be low.
Coding the Hadoop Job¶
A glance at the chart from last chapter tells us that the key and key confidence are stored at indices 23 and 24 respectively and that the mode and mode confidence are stored at indices 21 and 22 respectively.
Armed with this information we can write a mapper that emits a key signature as a key and the confidence as a value. We’ll also perform a basic sanity check on our data by testing to see if all 25 fields are present. It’s good practice to sanity check data in the mapper because you can never be certain that your data is pure.
Our mapper looks like this:
1 2 3 4 5 6 | def mapper(key, value):
data = value.split('\t')
if len(data) == 25:
keySig = (data[23], data[21])
confidence = float(data[24]) * float(data[22])
Wmr.emit(keySig, confidence)
|
Note
Remember, WMR interprets all keys and values as strings, however we’re using a tuple as a key and a float as a value. This is okay since they get automatically cast by WMR, we just have to remember to recast them in the reducer. Python’s eval() method is useful for getting tuples from strings
Our reducer will sum up all of the confidences. This way songs that have higher confidences will have more influence on the total than songs with uncertain keys. It also turns the key signatures from numbers into something more human readable. Doing the conversion in the reducer instead of the mapper saves a lot of work because, the calculation is only performed once per each of the 24 keys rather than once per each of the million songs
1 2 3 4 5 6 7 8 9 10 | def reducer(key, values):
keys = ['C','C#','D','D#','E','F','F#','G','G#','A','A#','B']
keySig, mode = eval(key)
keySig = keys[int(keySig)]
if mode == '0':
keySig += 'm'
count = 0.0
for value in values:
count += float(value)
Wmr.emit(key, count)
|
After running the job we find that the most common key is G major and the least common is D#/E flat minor.
Going Further¶
Why is G the most popular key? One reason could be the guitar. The fingerings for chords in the key of G are all very simple so maybe artists pick to G because it’s easy. If this theory is true, then genres like rock and country that use more guitars should use the key of G more often than genres like Hip Hop and electronic.
Unfortunately our dataset only has artist level tags, so we will need to create a filtering job that only outputs songs by artists who have been tagged with a specific genre.
This means that our hadoop job will have to read input from both the terms file and the metadata file. We can do this by using /shared/lastfm/ as the input path. Since it is a folder, all of the files in the folder are used as input. We want to pull different pieces of information from each of these files
- From metadata: the key signature and confidence of a song
- From terms: whether the genre is in the terms list and has a weight greater than 0.5
We want to send all of this information to the reducers sorted by artist. The artist ID of a song is at index 5 of the metadata file and the artist ID is at index 0 in the terms file. We can let the reducer know what information is being passed to it by emitting tuples where the first value is a flag stating what the second value is.
With this information we can write a mapper (genreMapper.py).. Remember to perform the sanity check on the metadata. Unfortunately we can’t run the same check on the other files because they have variable line lengths.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def mapper(key, value):
genre = "rock"
data = value.split('\t')
if key == "metadata" and len(data) == 25:
artist = data[5]
keySig = (data[23], data[21])
confidence = float(data[24]) * float(data[22])
Wmr.emit(artist, ("song", (keySig, confidence)))
elif key == "term":
artist = data[0]
for triplet in data[1:]:
term, freq, weight = triplet.split(',')
if term == genre and float(weight) > 0.5:
Wmr.emit(artist, ("term", True))
|
Our reducer (genreReducer.py) will need to take all of this data and only emit the songs by artists who are tagged with the the genre.
1 2 3 4 5 6 7 8 9 10 11 12 | def reducer(key, values):
isMatch = False
songPairs = []
for value in values:
flag, data = eval(value)
if flag == "term":
isMatch = data
elif flag == "song":
songPairs.append(data)
if isMatch:
for keySig, confidence in songPairs:
Wmr.emit(keySig, confidence)
|
After running this job we are left with a list of key signatures and confidences. We still need to add up the confidences for each of the key signatures. We can do this by passing our list to the reducer (avgKeyReducer.py) from the first part of this module. To use the output of a Wmr job as input for another, just click the ‘Use Output’ on either the top or the bottom of the page.
To pass our data straight to the reducer we’ll use what’s known as the identity mapper:
1 2 | def mapper(key, value):
Wmr.emit(key, value)
|
Try running this compound job for different values of genre. All of the tags in the terms file are lowercase. Once you’ve finished make a graph of the percentage of songs that are in each key per genre. It should look something like this:
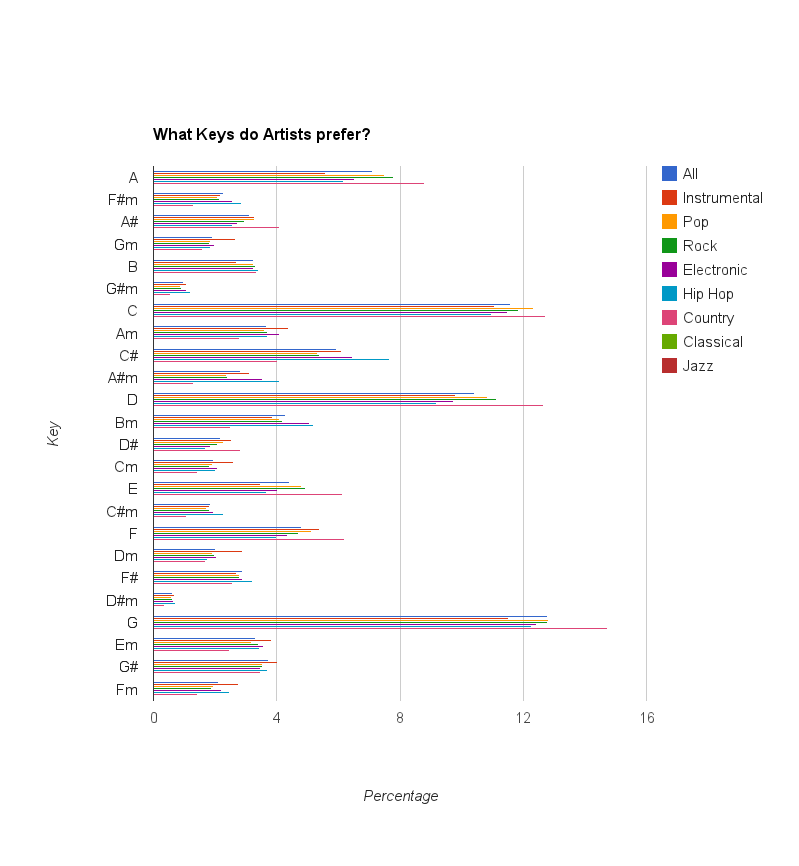
Interpreting the results¶
It looks like G is the most popular key for every genre but classical where it barely looses out to C. In country music G is a heavy favorite along with C and D which are also relatively easy keys to play on the guitar. However G is also very popular in electronic and hip hop, genres where the voice is often the only acoustic instrument.
Overall it seems like the guitar does have some effect on an artist’s choice of key, but it can’t be explained by guitar tuning alone.
Challenge¶
Can you find a way to find the counts for 6 different genres using only one chain of jobs?
