Parallel Displays of the Area Under the Curve¶
Here we will run the code for various types of data decomposition patterns using OpenMP, MPI, or a combination of MPI and OpenMP.
OpenMP Versions: Shared Memory multicore with threads¶
In code that uses OpenMP, the processing unit executing the computation of the area of each rectangle is a thread executing on a core of a shred-memory multicore computer. Let’s try a few examples of how OpenMP can map threads to rectangles to be computed. We consider these rectangles to be computed from left to right, forming a linear set of data values to be computed.
In these visualizations, we run the code in real time as it would get run in openMP, keeping information about which thread computed which rectangle. The program then displays back which thread computed each rectangle by playing back the recorded information and coloring the rectangles with different color for each thread.
Equal chunks of rectangles¶
Try running this script like this on the command line, in the area directory:
./run_openmp_equalChunks
You should see that four threads each computed consecutive equal-sized chunks of rectangles (we sometimes also call this division of work the ‘blocks’ decomposition). This is a well-used pattern of how to split the work, or decompose the problem, among the threads. This same pattern is also used frequently in distributed, message passing situations.
Note
Though the playback in these visualizations may appear to be serial, the threads did run concurrently. We unfortunately have no way of displaying rectangles on the screen in parallel!
Chunks of one, statically assigned¶
Rather than equal chunks where the size of a chunk that a thread works on is 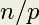 , where
, where 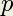 is the number of threads and
is the number of threads and 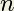 is the number of rectangles, another possible distribution of work is to have each thread compute one rectangle of the first rectangles, then go on a compute one of the next group of rectangles, and so on. If the thread to rectangle assignment is done statically ahead of time, it would look like the results of running this script:
is the number of rectangles, another possible distribution of work is to have each thread compute one rectangle of the first rectangles, then go on a compute one of the next group of rectangles, and so on. If the thread to rectangle assignment is done statically ahead of time, it would look like the results of running this script:
./run_openmp_chunksOfOneStatic
It should look like this when it completes:
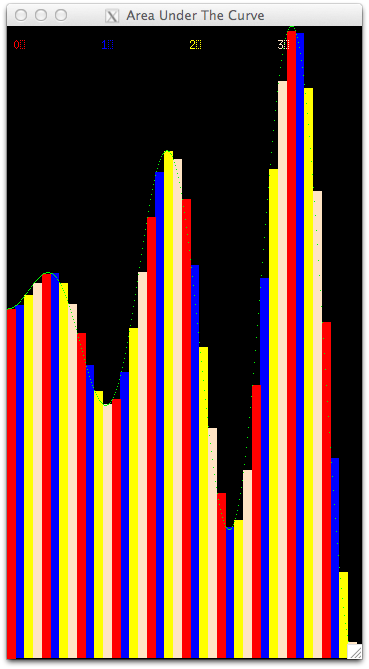
Note the legend at the top of the window tells you the color for each thread, which are numbered from 0 through 3 for this case. Study this to be certain you understand the assignment of threads to rectangles.
OpenMP can decide for itself which threads will work on which computational elements. This is know as dynamic scheduling. Try this script for that and see what you observe. This could be different on different machines and could change each time you run it.
./run_openmp_chunksOfOneDynamic
MPI Examples: distributed message passing¶
In MPI, the processing units that run in parallel are processes, which are either running on the same machine or more likely across a cluster of machines, where each machine starts its own process.
Equal chunks of rectangles¶
In the case of a cluster of machines, there is one data decomposition pattern that makes the most sense, and that is to partition the work into equal chunks. Try this script to visualize that case:
./run_mpi_equalChunks
You should see multiple windows displayed, one for each process, with rectangles assigned and computed in the order that they appear inside the function. It should look like this:

Chunks of one, statically assigned¶
Another possible assignment, especially for a single machine running MPI processes, is to have the processes compute one rectangle each, similar to the single chunk case for OpenMP. Run this and you will see it looks the same as the mapping for OpenMP:
./run_mpi_chunksOfOne
Hybrid: MPI plus OpenMP¶
When using MPI across a cluster of machines, if those machines have multicore processors, then each of them can execute code using OpenMP. The following example script runs this case, where each MPI process gets an equal chunk of the original rectangles, and those chunks are further divided by OpenMP threads.
./run_mpi-openmp_equalChunks
The result for this decomposition looks like this:
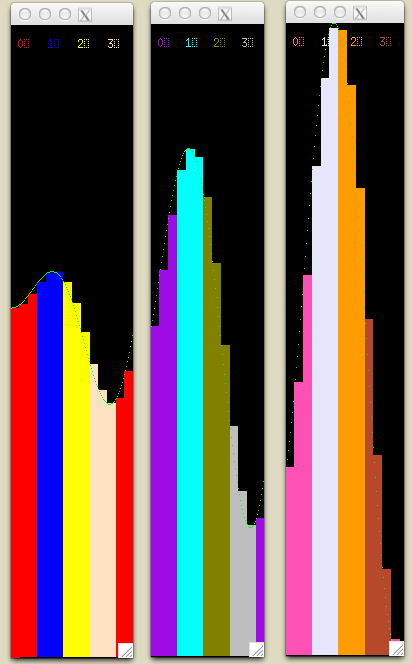
There are other possible hybrid combinations- please experiment with some of the other scripts beginning with run_ that we haven’t mentioned here yet to see if you can determine these more complicated patterns.
