Counting Pease With MapReduce¶
Word Frequency¶
We will discuss a classic example called Word Frequency, or Word Count. In this example, the goal is to identify the set of unique words in a text file and compute their associated “counts” or frequencies. Consider the follow poem by Mother Goose:
Pease-porridge hot
Pease-porridge cold
Pease-porridge in the pot
Nine days old
Some like it hot
Some like it cold
Some like it in the pot
Nine days old
If we were to count the word frequencies in this file, we may get output that looks like the following:
cold : 2
days : 2
hot : 2
in : 2
it : 3
like : 3
nine : 2
old : 2
pease-porridge : 3
pot : 2
some : 3
the : 2
Notice that each word is associated with the frequency of its occurrence in the poem.
Solving the Problem Using MapReduce¶
In MapReduce, the programmer is responsible for mainly writing two serial
functions: map() and reduce(). The framework takes care of running
everything in parallel. The components of the system are as follows:
- The
map()function takes a chunk of input, processes it, and outputs a series of (key, value) pairs. All instances of themap()function (mappers) run independently and simultaneously. This is known as the Map phase. - A Combiner function sorts all the (key,value) pairs coming from the Map phase. The combiner uses a hashing function to aggregate all the values associated with a particular key. Thus, the ouput from the combiner is a series of (key,list(value)) pairs.
- The
reduce()function takes (key, list(value)) pairs and performs a reduction operation on each. A reduction operation is any operation that combines the values in some way. The output is a final (key, value) pair, where the value is the result of the reduction operation performed on the list. Each instance of the reduce() function (reducer) run independently and in parallel.
So how do we calculate Word Frequency with MapReduce? In the following example,
we have three mappers and three reducers. For simplicity, we assume that the
file is split on new lines (\n) although this need not always be the case. Each
mapper takes its assigned chunk of text and splits it into words, and
emits (key,value) pairs where the key is an individual word, and the value is 1.
If multiple instances of a word are assigned to the same mapper, the local
frequencies can be added and emitted instead.
Below, we have an illustration of the Map phase of the algorithm. Observe that
the first mapper is emitting a single (key,value) pair of (Pease-porridge,3) instead
of three instances of the pair (Pease-porridge, 1). Notice that all mappers run
in parallell. This assumes that a local combination operation is occuring.
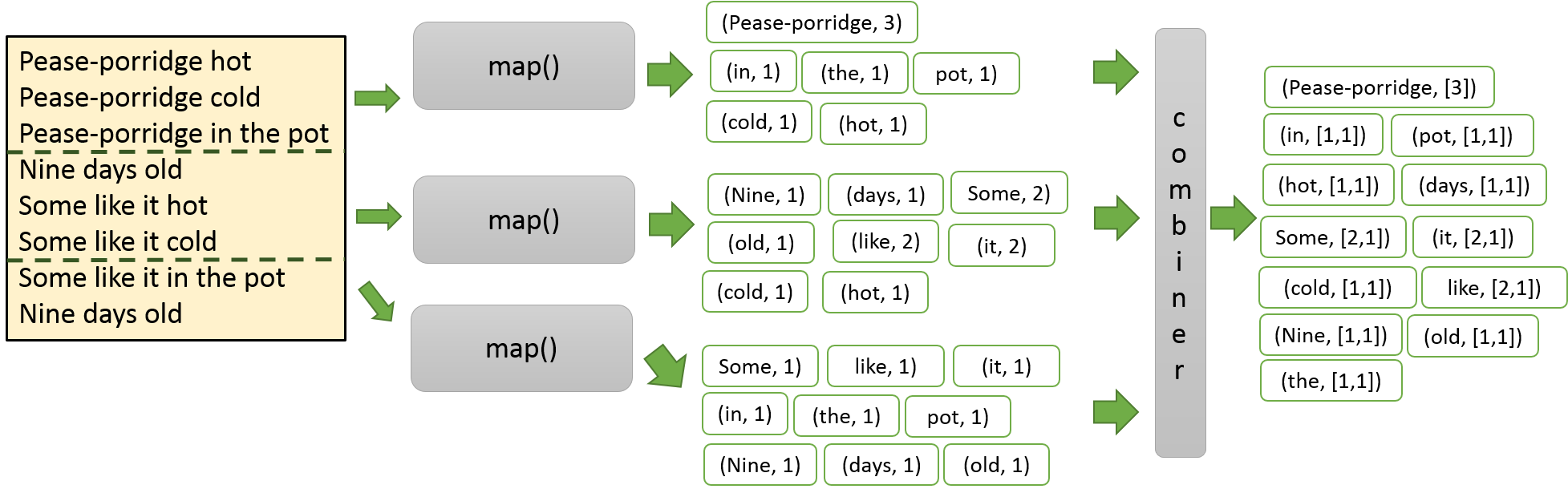
Figure 1: How the Map Phase of the algorithm works.
The combiner acts as a synchronization point; all the mappers must finish prior
to the combiner finishing execution. The combiner constructs (key,list(value)) pairs from the output from the mappers. For example, mapper 2 produced
the (key,value) pair (it, 2), while mapper 3 produced the (key,value)
pair (it, 1). The combiner will aggregate these two pairs and output
(it, [2,1]).
After the combiner finishes executing, the (key,list(value)) pairs go to to
the reducers for processing. We refer to this as the Reduce phase. The figure
below illustrates the Reduce phase for this example. Each reducer gets assigned
a set of (key,list(value)) pairs. For each pair, it performs a reduction
operation. In this case, the reduction operation is addition; all the values
in the list are simply added together. For example, reducer 2 reduces the pair
(Some, [2,1]) to (Some, 3).
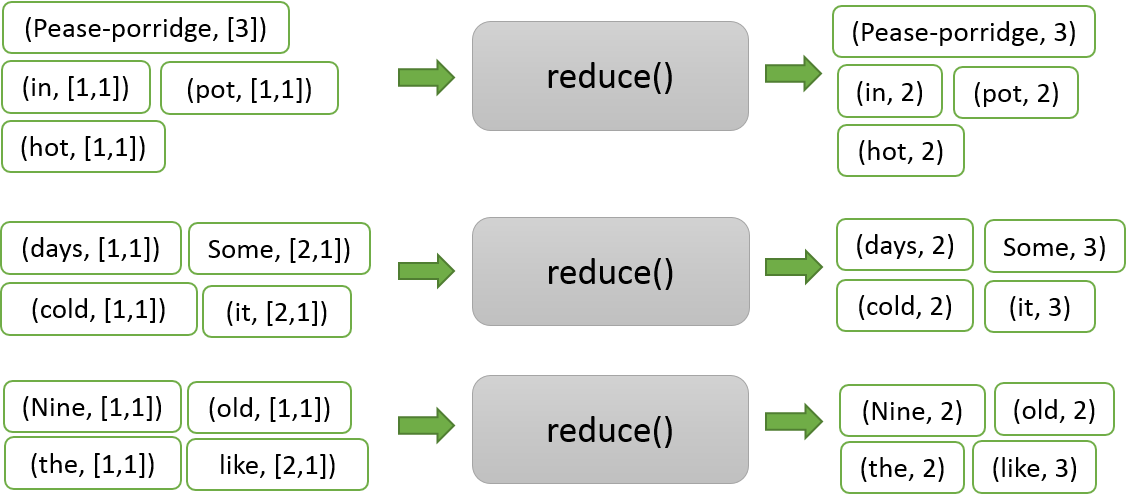
Figure 2: How the Reduce Phase of the algorithm works.
Note
One thing we do not discuss here is fault tolerance. Fault tolerance is most important for large distributed systems. When you have that many computers networked together, it’s likely that some subset of them will fail. Fault tolerance allows us to recover from failures on the fly. In the case of Google’s Mapreduce, fault tolerance is maintained by constantly pinging nodes. If any node stays silent for too long, the framework marks that node as being “dead”, and redistributes its work to other worker nodes. Phoenix and Phoenix++ both have fault tolerance protections. Phoenix++ has an optional execution mode that enables a user to skip data records in the case of segmentation faults and bus errors. This can be invoked through the use of the signal handler.
