Data Decomposition Algorithm Strategies and Related Coordination Strategies¶
5. Shared Data Decomposition Algorithm Strategy: chunks of data per thread using a parallel for loop implementation strategy¶
file: Vath_pth/05.parallelLoop-equalChunks/parallelLoopEqualChunks.C
Build inside 05.parallelLoop-equalChunks directory:
make parallelLoopEqualChunks
Execute on the command line inside 05.parallelLoop-equalChunks directory:
./parallelLoopEqualChunks 4
Replace 4 with other values for the number of threads, or leave off
An iterative for loop is a remarkably common pattern in all programming, primarily used to perform a calculation N times, often over a set of data containing N elements, using each element in turn inside the for loop. If there are no dependencies between the calculations (i.e. the order of them is not important), then the code inside the loop can be split between forked threads. When doing this, a decision the programmer needs to make is to decide how to partition the work between the threads by answering this question:
- How many and which iterations of the loop will each thread complete on its own?
We refer to this as the data decomposition pattern because we are decomposing the amount of work to be done (typically on a set of data) across multiple threads. In the following code, this is done in Pthreads by using the vath library function ThreadRange() inside of the thread function (line 39) in the following code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | /*
* Using Victor Alessandrini's vath_pth library.
*
* parallelLoopEqualChunks.C
* ... illustrates the use of parallel for loop in which
* threads iterate through equal sized chunks of the index range
* Ex. thread 1 [0, 1, 2 ... 7], thread 2 [8, 9 ... 15]
*
* Modeled from code provided by Joel Adams, Calvin College, November 2009.
* Hannah Sonsalla, Macalester College, 2017.
*
* Usage: ./parallelLoopEqualChunks [numThreads]
*
* Exercise
* - Compile and run, comparing output to source code
* - try with different numbers of threads, e.g.: 2, 3, 4, 6, 8
*/
#include <stdlib.h>
#include <stdio.h>
#include <SPool.h>
#include <pthread.h>
SPool *TH;
const int REPS = 16;
// -------------------
// Worker threads code
// -------------------
void thread_fct(void *idp) {
// ThreadRange() computes index range for worker thread from index range.
// Function knows rank of worker thread and number of threads.
int beg, end;
beg = 0; // initialize [beg, end) to global range
end = REPS;
TH->ThreadRange(beg, end); // now [beg, end) is sub-range for this thread
int rank = TH->GetRank();
for (int i = beg; i < end; i++) {
printf("Thread %d performed iteration %d\n", rank, i);
}
}
int main(int argc, char **argv) {
int numThreads;
if(argc==2) numThreads = atoi(argv[1]);
else numThreads = 4;
TH = new SPool(numThreads);
TH->Dispatch(thread_fct, NULL);
TH->WaitForIdle();
delete TH;
return 0;
}
|
Once you run this code, verify that the default behavior for this function is this sort of decomposition of iterations of the loop to threads, when you set the number of threads to 4 on the command line:
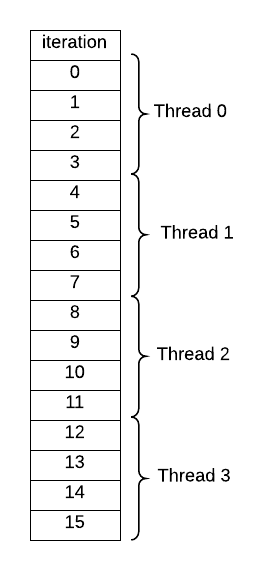
What happens when the number of iterations (16 in this code) is not evenly divisible by the number of threads? Try several cases to be certain how the compiler splits up the work. This type of decomposition is commonly used when accessing data that is stored in consecutive memory locations (such as an array) that might be cached by each thread.
8. Coordination Using Collective Communication: Reduction¶
file: Vath_pth/08.reduction/reduction.C
Build inside 08.reduction directory:
make reduction
Execute on the command line inside 08.reduction directory:
./reduction 4
Replace 4 with other values for the number of threads, or leave off
Once threads have performed independent concurrent computations, possibly on some portion of decomposed data, it is quite common to then reduce those individual computations into one value. This type of operation is called a collective communication pattern because the threads must somehow work together to create the final desired single value.
In this example, an array of randomly assigned doubles represents a set of shared data (a more realistic program would perform a computation that creates meaningful data values; this is just an example). Note the common sequential code pattern found in the function called sequentialSum in the code below (starting line 58): a for loop is used to sum up all the values in the array.
Next let’s consider how this can be done in parallel with threads. Somehow the threads must communicate to keep the overall sum updated as each of them works on a portion of the array. The Reduction <T> utility from the vath library is used. This class contains a mutex that guards operations that are performed on the shared variable. A Reduction object is created on line 32 that can be used to accumulate the values in the array. In the thread worker function, line 52 shows how to sum partial results to a shared variable. Each thread has the shared variable accumulate their partial result. Therefore, at completion all values in the array are summed together.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 | /*
* reduction.C
*
* Using Victor Alessandrini's vath_pth library.
* ... illustrates use of reduction
*
* Modeled from code provided by Joel Adams, Calvin College, November 2009.
* Hannah Sonsalla, Macalester College, 2017.
*
* Usage: ./reduction [numThreads]
*
* Exercise:
* - Compile and run. Note that correct output is produced by
* sequential sum (sequentialSum) and parallel sum with reduction
* (reductionSum & RD). Incorrect output is obtained by parallel
* sum without using reduction (noReduceSum).
*/
#include <stdlib.h>
#include <stdio.h>
#include <SPool.h>
#include <pthread.h>
#include <Rand.h> // random generator
#include <Reduction.h> // reduction
#define SIZE 1000000
// global variables
double array[SIZE];
double noReduceSum; // used for parallel sum w/out reduction
Reduction<double> RD; // Reduction: accumulator of doubles
SPool *TH;
// -------------------
// Worker threads code for parallel sum (with and without reduction)
// -------------------
void thread_fct(void *idp) {
double reductionSum = 0.0;
int beg, end;
beg = 0;
end = SIZE;
TH->ThreadRange(beg, end);
for(int i=beg; i<end; i++) {
reductionSum += array[i]; // accumulate results in parallel reduction sum
noReduceSum += array[i]; // and sum without reduction
}
RD.Accumulate(reductionSum); // Reduction: accumulate double parallelSum indside RD
}
// -------------------
// Sequential sum
// -------------------
double seqSum(double *a, int n) {
double sum = 0;
for(int i=0; i<n; i++) sum += array[i];
return sum;
}
// -------------------
// Initialize array with random values in [0, 1]
// -------------------
void initialize(double *a, int n) {
Rand R(999); // random generator
for(int i=0; i<n; i++) array[i] = R.draw();
}
int main(int argc, char **argv) {
int numThreads;
double sequentialSum;
if(argc==2) numThreads = atoi(argv[1]);
else numThreads = 4;
/* Fill array with random numbers*/
initialize(array, SIZE);
/* Sum the array sequentially */
sequentialSum = seqSum(array, SIZE);
/* Sum array using multiple threads */
TH = new SPool(numThreads);
TH->Dispatch(thread_fct, NULL);
TH->WaitForIdle();
/* Results */
printf("\n Sequential sum = %.2f \n", sequentialSum);
printf("\n Parallel sum without reduction = %.2f \n", noReduceSum);
printf("\n Parallel sum with reduction = %.2f \n\n", RD.Data());
delete TH;
return 0;
}
|
Something to think about¶
Do you have an ideas about why the parallel version without reduction did not produce the correct result? Later examples will hopefully shed some light on this.
9. Coordination Using Collective Communication: Reduction revisited¶
file: Vath_pth/09.reduction2/reduction2.C
Build inside 09.reduction2 directory:
make reduction2
Execute on the command line inside 09.reduction2 directory:
./reduction2 4 8192
Replace 4 with other values for the number of threads
Replace 8192 with other values for n (computing up to n factorial)
The next example uses many threads to generate computations of factorials of n. Though there are likely other better ways to compute factorials, this example uses a very simple approach to illustrate how reduction can be used with the multiplication operation instead of addition in the previous example. This is shown on line 56 in the code below, which also makes use of an additional C++ file, BigInt.h:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 | /*
* reduction2.C
*
* Using Victor Alessandrini's vath_pth library.
* ... computes factorial values, using Owen Astrachan's
* BigInt class to explore reductions
*
* Modeled from code provided by Joel Adams, Calvin College, November 2009.
* Hannah Sonsalla, Macalester College, 2017.
*
* Usage: ./reduction2 [numThreads] [n]
*
* Exercise:
* - Build and run, record sequential time in a spreadsheet.
* - Uncomment line B and comment out line A. Rerun in parallel
* noting the reduction for a BigInt using 2, 4, 6, 8, ... threads,
* recording the wall times in the spreadsheet.
* - Create a chart that plots the times vs the # of threads.
* - Experiment with different n values
*/
#include <stdlib.h>
#include <SPool.h>
#include <pthread.h>
#include <cassert>
#include <CpuTimer.h> // CPU timer
#include <Reduction.h> // reduction
#include "BigInt.h"
// global variables
unsigned n;
unsigned numThreads;
Reduction<BigInt> RD; // Reduction
SPool *TH;
// -------------------
// Worker threads code for parallel factorial
// -------------------
void thread_fct(void *idp) {
int beg, end;
beg = 2;
end = n;
TH->ThreadRange(beg, end); // sub-range
BigInt result = 1;
int rank = TH->GetRank();
for(unsigned i=beg; i<end; i++) {
result *= i;
}
if (rank == numThreads) result *= end; // If last thread, multiply by n = end
RD.Multiply(result); // Reduction: multiply global reduction variable by result
}
// -------------------
// Factorial function for multithreading
// -------------------
BigInt parFactorial(unsigned number){
n = number;
BigInt result = 1; // If 0! or 1! return 1
if (n > 1) {
RD.Accumulate(1);
TH->Dispatch(thread_fct, NULL);
TH->WaitForIdle();
result = RD.Data();
RD.Reset();
}
return result;
}
// -------------------
// Sequential factorial
// -------------------
BigInt seqFactorial(unsigned number) {
BigInt result = 1;
for (unsigned i = 2; i <= number; i ++) {
result *= i;
}
return result;
}
int main(int argc, char **argv) {
n = 8192;
numThreads = 1;
CpuTimer TR;
switch (argc) {
case 3: n = atoi(argv[2]);
case 2: numThreads = atoi(argv[1]);
case 1: break;
default: cout << "\nUsage: ./reduction2 [numThreads] [n]\n\n";
}
/* Calculate factorial */
BigInt result;
TH = new SPool(numThreads);
TR.Start();
result = seqFactorial(n); // A
//result = parFactorial(n); // B
TR.Stop();
cout << "Computed " << n << "! using " << numThreads << " thread " << endl;
TR.Report();
// run a few tests to validate the results
assert( parFactorial(0) == 1 );
assert( parFactorial(1) == 1 );
assert( parFactorial(2) == 2 );
assert( parFactorial(3) == 6 );
assert( parFactorial(4) == 24 );
assert( parFactorial(5) == 120 );
assert( parFactorial(32) == BigInt("263130836933693530167218012160000000") );
assert( parFactorial(100) == BigInt( string("9332621544394415268169923885")
+ "6266700490715968264381621468"
+ "5929638952175999932299156089"
+ "4146397615651828625369792082"
+ "7223758251185210916864000000"
+ "000000000000000000" ) );
cout << "All tests passed!\n" << flush;
delete TH;
return 0;
}
|
With this code you can begin to explore the time it takes to execute the program when using increasing numbers of threads for various values of n. Follow the instructions at the top of the file.
