Data Decomposition Algorithm Strategies and Related Coordination Strategies¶
6. Shared Data Decomposition Algorithm Strategy: chunks of data per thread using a parallel for loop implementation strategy¶
file: openMP/06.parallelLoop-equalChunks/parallelLoopEqualChunks.c
Build inside 06.parallelLoop-equalChunks directory:
make parallelLoopEqualChunks
Execute on the command line inside 06.parallelLoop-equalChunks directory:
./parallelLoopEqualChunks 4
Replace 4 with other values for the number of threads, or leave off
An iterative for loop is a remarkably common pattern in all programming, primarily used to perform a calculation N times, often over a set of data containing N elements, using each element in turn inside the for loop. If there are no dependencies between the calculations (i.e. the order of them is not important), then the code inside the loop can be split between forked threads. When doing this, a decision the programmer needs to make is to decide how to partition the work between the threads by answering this question:
- How many and which iterations of the loop will each thread complete on its own?
We refer to this as the data decomposition pattern because we are decomposing the amount of work to be done (typically on a set of data) across multiple threads. In the following code, this is done in OpenMP using the omp parallel for pragma just in front of the for statement (line 27) in the following code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | /* parallelLoopEqualChunks.c
* ... illustrates the use of OpenMP's default parallel for loop in which
* threads iterate through equal sized chunks of the index range
* (cache-beneficial when accessing adjacent memory locations).
*
* Joel Adams, Calvin College, November 2009.
*
* Usage: ./parallelLoopEqualChunks [numThreads]
*
* Exercise
* - Compile and run, comparing output to source code
* - try with different numbers of threads, e.g.: 2, 3, 4, 6, 8
*/
#include <stdio.h> // printf()
#include <stdlib.h> // atoi()
#include <omp.h> // OpenMP
int main(int argc, char** argv) {
const int REPS = 16;
printf("\n");
if (argc > 1) {
omp_set_num_threads( atoi(argv[1]) );
}
#pragma omp parallel for
for (int i = 0; i < REPS; i++) {
int id = omp_get_thread_num();
printf("Thread %d performed iteration %d\n",
id, i);
}
printf("\n");
return 0;
}
|
Once you run this code, verify that the default behavior for this pragma is this sort of decomposition of iterations of the loop to threads, when you set the number of threads to 4 on the command line:
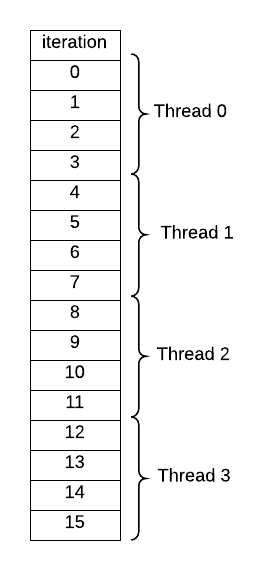
What happens when the number of iterations (16 in this code) is not evenly divisible by the number of threads? Try several cases to be certain how the compiler splits up the work. This type of decomposition is commonly used when accessing data that is stored in consecutive memory locations (such as an array) that might be cached by each thread.
8. Coordination Using Collective Communication: Reduction¶
file: openMP/08.reduction/reduction.c
Build inside 08.reduction directory:
make reduction
Execute on the command line inside 08.reduction directory:
./reduction 4
Replace 4 with other values for the number of threads, or leave off
Once threads have performed independent concurrent computations, possibly on some portion of decomposed data, it is quite common to then reduce those individual computations into one value. This type of operation is called a collective communication pattern because the threads must somehow work together to create the final desired single value.
In this example, an array of randomly assigned integers represents a set of shared data (a more realistic program would perform a computation that creates meaningful data values; this is just an example). Note the common sequential code pattern found in the function called sequentialSum in the code below (starting line 51): a for loop is used to sum up all the values in the array.
Next let’s consider how this can be done in parallel with threads. Somehow the threads must implicitly communicate to keep the overall sum updated as each of them works on a portion of the array. In the parallelSum function, line 64 shows a special clause that can be used with the parallel for pragma in OpenMP for this. All values in the array are summed together by using the OpenMP parallel for pragma with the reduction(+:sum) clause on the variable sum, which is computed in line 66.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | /* reduction.c
* ... illustrates the OpenMP parallel-for loop's reduction clause
*
* Joel Adams, Calvin College, November 2009.
*
* Usage: ./reduction
*
* Exercise:
* - Compile and run. Note that correct output is produced.
* - Uncomment #pragma in function parallelSum(),
* but leave its reduction clause commented out
* - Recompile and rerun. Note that correct output is NOT produced.
* - Uncomment 'reduction(+:sum)' clause of #pragma in parallelSum()
* - Recompile and rerun. Note that correct output is produced again.
*/
#include <stdio.h> // printf()
#include <omp.h> // OpenMP
#include <stdlib.h> // rand()
void initialize(int* a, int n);
int sequentialSum(int* a, int n);
int parallelSum(int* a, int n);
#define SIZE 1000000
int main(int argc, char** argv) {
int array[SIZE];
if (argc > 1) {
omp_set_num_threads( atoi(argv[1]) );
}
initialize(array, SIZE);
printf("\nSeq. sum: \t%d\nPar. sum: \t%d\n\n",
sequentialSum(array, SIZE),
parallelSum(array, SIZE) );
return 0;
}
/* fill array with random values */
void initialize(int* a, int n) {
int i;
for (i = 0; i < n; i++) {
a[i] = rand() % 1000;
}
}
/* sum the array sequentially */
int sequentialSum(int* a, int n) {
int sum = 0;
int i;
for (i = 0; i < n; i++) {
sum += a[i];
}
return sum;
}
/* sum the array using multiple threads */
int parallelSum(int* a, int n) {
int sum = 0;
int i;
// #pragma omp parallel for // reduction(+:sum)
for (i = 0; i < n; i++) {
sum += a[i];
}
return sum;
}
|
Something to think about¶
Do you have an ideas about why the parallel for pragma without the reduction clause did not produce the correct result? Later examples will hopefully shed some light on this.
9. Coordination Using Collective Communication: Reduction revisited¶
Build inside 09.reduction-userDefined directory:
make reduction2
Execute on the command line inside 09.reduction-userDefined directory:
./reduction 4 4096
Replace 4 with other values for the number of threads
Replace 4096 with other values for n (computing up to n factorial)
The next example uses many threads to generate computations of factorials of n. Though there are likely other better ways to compute factorials, this example uses a very simple approach to illustrate how reduction can be used with the multiplication operation instead of addition in the previous example. The pragma for this is on line 34 in the code below, which also makes use of an additional C++ file, BigInt.h:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | /* reduction2.cpp computes a table of factorial values,
* using Owen Astrachan's BigInt class to explore
* OpenMP's user-defined reductions.
*
* Joel Adams, Calvin College, December 2015.
*
* Usage: ./reduction2 [numThreads] [n]
*
* Exercise:
* - Build and run, record sequential time in a spreadsheet
* - Uncomment #pragma omp parallel for directive, rebuild,
* and read the error message carefully.
* - Uncomment the #pragma omp declare directive, rebuild,
* and note the user-defined * reduction for a BigInt.
* - Rerun, using 2, 4, 6, 8, ... threads, recording
* the times in the spreadsheet.
* - Create a chart that plots the times vs the # of threads.
* - Experiment with different n values
*/
#include "BigInt.h"
#include <cassert>
#include <omp.h>
/*
#pragma omp declare reduction(*: BigInt: \
omp_out = omp_out * omp_in) \
initializer( omp_priv=BigInt(1))
*/
BigInt factorial(unsigned n) {
BigInt result = 1;
// #pragma omp parallel for reduction(*:result)
for (unsigned i = 2; i <= n; i += 1) {
result *= i;
}
return result;
}
int main(int argc, char** argv) { // on a 2GHz i7 CPU:
unsigned n = 4096; // ~10 secs sequentially
unsigned numThreads = 1;
switch (argc) {
case 3: n = atoi(argv[2]);
case 2: numThreads = atoi(argv[1]);
case 1: break;
default: cout << "\nUsage: ./reduction2 [numThreads] [n]\n\n";
}
omp_set_num_threads(numThreads);
double startTime = omp_get_wtime();
BigInt nFactorial = factorial(n);
double time = omp_get_wtime() - startTime;
cout << "Computing " << n << "! using "
<< numThreads << " threads took: "
<< time << " secs" << endl;
// run a few tests to validate the results
assert( factorial(0) == 1 );
assert( factorial(1) == 1 );
assert( factorial(2) == 2 );
assert( factorial(3) == 6 );
assert( factorial(4) == 24 );
assert( factorial(5) == 120 );
assert( factorial(32) == BigInt("263130836933693530167218012160000000") );
assert( factorial(100) == BigInt( string("9332621544394415268169923885")
+ "6266700490715968264381621468"
+ "5929638952175999932299156089"
+ "4146397615651828625369792082"
+ "7223758251185210916864000000"
+ "000000000000000000" ) );
cout << "All tests passed!\n" << flush;
}
|
With this code you can begin to explore the time it takes to execute the program when using increasing numbers of threads for various values of n. Follow the instructions at the top of the file.
10. Dynamic Data Decomposition¶
Build inside 10.parallelLoop-dynamicSchedule directory:
make dynamicScheduling
Execute on the command line inside 10.parallelLoop-dynamicSchedule directory:
./dynamicScheduling 4
Replace 4 with other values for the number of threads
The following example computes factorials for the numbers 2 through 512, placing the result in an array. This array of results is the data in this data decomposition pattern. Since each number will take a different amount of time to compute, this is a case where using dynamic scheduling of the work improves the performance. Try the tasks lsited in the header of the code shown below to see this.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | /* dynamicScheduling.cpp computes a table of factorial values,
* using Owen Astrachan's BigInt class to explore
* OpenMP's schedule() clause.
*
* @author: Joel Adams, Calvin College, Dec 2015.
*
* Usage: ./dynamicScheduling [numThreads]
*
* Exercise:
* - Build and run, record sequential run time in a spreadsheet
* - Uncomment #pragma omp parallel for, rebuild,
* run using 2, 4, 6, 8, ... threads, record run times.
* - Uncomment schedule(dynamic), rebuild,
* run using 2, 4, 6, 8, ... threads, record run times.
* - Create a line chart plotting run times vs # of threads.
*/
#include "BigInt.h" // class BigInt
#include <omp.h> // OpenMP functions
#include <cassert> // assert()
/* factorial(n) computes n!
* @param: n, an unsigned int.
* @return: n!, a BigInt.
*/
BigInt factorial(unsigned n) {
BigInt result = 1; // 0! or 1!
for (unsigned i = 2; i <= n; ++i) {
result *= i;
}
return result;
}
int main(int argc, char** argv) { // on a 2 GHz i7 CPU:
const unsigned MAX = 512; // ~14 secs sequentially
// const unsigned MAX = 800; // ~60 secs sequentially
BigInt factorialTable[MAX+1];
if (argc > 1) { omp_set_num_threads( atoi(argv[1]) ); }
cout << "\nDepending on the speed of your computer,"
<< "\n this program may take a while to complete,"
<< "\n so please wait patiently...\n" << endl;
double startTime = omp_get_wtime();
// #pragma omp parallel for // schedule(dynamic)
for (unsigned i = 0; i <= MAX; i++) {
factorialTable[i] = factorial(i);
}
double totalTime = omp_get_wtime() - startTime;
cout << "Computing 0! .. " << MAX << "! took: "
<< totalTime << " secs\n" << endl;
// run a few tests to validate the results
assert( factorialTable[0] == 1 );
assert( factorialTable[1] == 1 );
assert( factorialTable[2] == 2 );
assert( factorialTable[3] == 6 );
assert( factorialTable[4] == 24 );
assert( factorialTable[5] == 120 );
assert( factorialTable[32] == BigInt("263130836933693530167218012160000000") );
assert( factorialTable[100] == BigInt( string("9332621544394415268169923885")
+ "6266700490715968264381621468"
+ "5929638952175999932299156089"
+ "4146397615651828625369792082"
+ "7223758251185210916864000000"
+ "000000000000000000" ) );
cout << "All tests passed!\n" << endl;
}
|
