Barrier Synchronization, Timing and Tags¶
16. The Barrier Coordination Pattern¶
file: patternlets/MPI/16.barrier/barrier.c
Build inside 16.barrier directory:
make barrier
Execute on the command line inside 16.barrier directory:
mpirun -np <number of processes> ./barrier
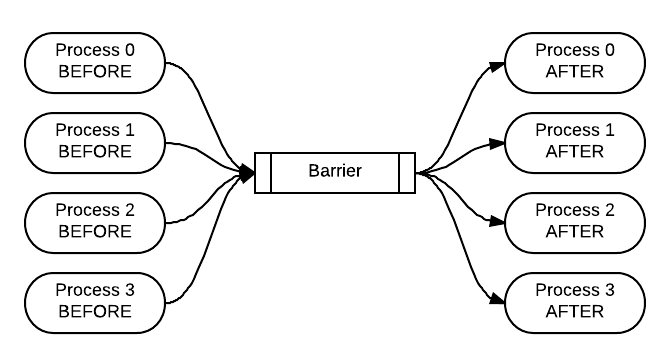
A barrier is used when you want all the processes to complete a portion of code before continuing. Use this exercise to verify that it is occurring when you add the call to the MPI_Barrier function. After adding the barrier call, the BEFORE strings should all be printed prior to all of the AFTER strings. You can visualize the execution of the program with the barrier function like this, with time moving from left to right:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | /* barrier.c
* ... illustrates the behavior of MPI_Barrier() ...
*
* Joel Adams, Calvin College, May 2013.
* Bill Siever, April 2016
* (Converted to master/worker pattern).
* Joel Adams, April 2016
* (Refactored code so that just one barrier needed).
*
* Usage: mpirun -np 8 ./barrier
*
* Exercise:
* - Compile; then run the program several times,
* noting the interleaved outputs.
* - Uncomment the MPI_Barrier() call; then recompile and rerun,
* noting how the output changes.
* - Explain what effect MPI_Barrier() has on process behavior.
*/
#include <stdio.h> // printf()
#include <mpi.h> // MPI
/* Have workers send messages to the master, which prints them.
* @param: id, an int
* @param: numProcesses, an int
* @param: hostName, a char*
* @param: position, a char*
*
* Precondition: this function is being called by an MPI process
* && id is the MPI rank of that process
* && numProcesses is the number of processes in the computation
* && hostName points to a char array containing the name of the
* host on which this MPI process is running
* && position points to "BEFORE" or "AFTER".
*
* Postcondition: each process whose id > 0 has sent a message to process 0
* containing id, numProcesses, hostName, and position
* && process 0 has received and output each message.
*/
#define BUFFER_SIZE 200
#define MASTER 0
void sendReceivePrint(int id, int numProcesses, char* hostName, char* position) {
char buffer[BUFFER_SIZE] = {'\0'};;
MPI_Status status;
if (id != MASTER) {
// Worker: Build a message and send it to the Master
int length = sprintf(buffer,
"Process #%d of %d on %s is %s the barrier.\n",
id, numProcesses, hostName, position);
MPI_Send(buffer, length+1, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
} else {
// Master: Receive and print the messages from all Workers
for(int i = 0; i < numProcesses-1; i++) {
MPI_Recv(buffer, BUFFER_SIZE, MPI_CHAR, MPI_ANY_SOURCE,
MPI_ANY_TAG, MPI_COMM_WORLD, &status);
printf("%s", buffer);
}
}
}
int main(int argc, char** argv) {
int id = -1, numProcesses = -1, length = -1;
char myHostName[MPI_MAX_PROCESSOR_NAME] = {'\0'};
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &id);
MPI_Comm_size(MPI_COMM_WORLD, &numProcesses);
MPI_Get_processor_name (myHostName, &length);
sendReceivePrint(id, numProcesses, myHostName, "BEFORE");
// MPI_Barrier(MPI_COMM_WORLD);
sendReceivePrint(id, numProcesses, myHostName, "AFTER");
MPI_Finalize();
return 0;
}
|
17. Timing code using the Barrier Coordination Pattern¶
file: patternlets/MPI/17.barrier+Timing/barrier+timing.c
Build inside 17.barrier+Timing directory:
make barrier+timing
Execute on the command line inside 17.barrier+Timing directory:
mpirun -np <number of processes> ./barrier+timing
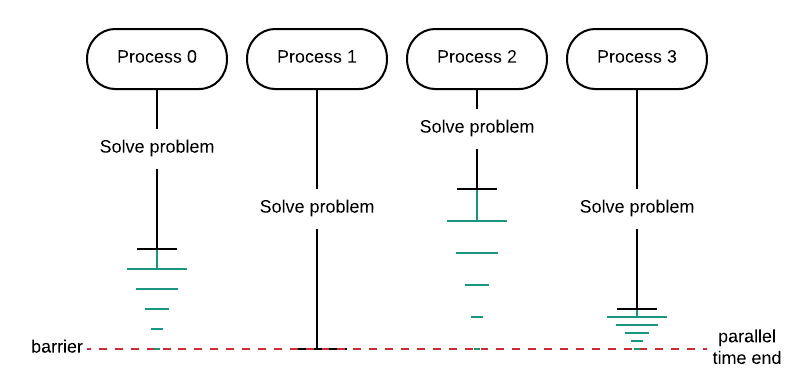
The primary purpose of this exercise is to illustrate that one of the most practical uses of a barrier is to ensure that you are getting legitimate timings for your code examples. By using a barrier, you ensure that all processes have finished before recording the time using the master process. If a process finishes before all processes have completed their portion, the process must wait as indicated in green in the diagram below. Thus, the parallel execution time is the time it took the longest process to finish.
To do:
Run the code several times and determine the average, median, and minimum execution time when the code has a barrier and when it does not. Without the barrier, what process is being timed?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | /* barrier+timing.c
* ... illustrates the behavior of MPI_Barrier()
* to coordinate process-timing.
*
* Joel Adams, April 2016
*
* Usage: mpirun -np 8 ./barrier+timing
*
* Exercise:
* - Compile; then run the program five times,
* - In a spreadsheet, compute the average,
* median, and minimum of the five times.
* - Uncomment the two MPI_Barrier() calls;
* then recompile, rerun five times, and
* compute the new average, median, and min
* times.
* - Why did uncommenting the barrier calls
* produce the change you observed?
*/
#include <stdio.h> // printf()
#include <mpi.h> // MPI
#include <unistd.h> // sleep()
#define MASTER 0
/* answer the ultimate question of life, the universe,
* and everything, based on id and numProcs.
* @param: id, an int
* @param: numProcs, an int
* Precondition: id is the MPI rank of this process
* && numProcs is the number of MPI processes.
* Postcondition: The return value is 42.
*/
int solveProblem(int id, int numProcs) {
sleep( ((double)id+1) / numProcs);
return 42;
}
int main(int argc, char** argv) {
int id = -1, numProcesses = -1;
double startTime = 0.0, totalTime = 0.0;
int answer = 0.0;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &id);
MPI_Comm_size(MPI_COMM_WORLD, &numProcesses);
// MPI_Barrier(MPI_COMM_WORLD);
if ( id == MASTER) {
startTime = MPI_Wtime();
}
answer = solveProblem(id, numProcesses);
// MPI_Barrier(MPI_COMM_WORLD);
if ( id == MASTER ) {
totalTime = MPI_Wtime() - startTime;
printf("\nThe answer is %d; computing it took %f secs.\n\n",
answer, totalTime);
}
MPI_Finalize();
return 0;
}
|
18. Timing code using the Reduction pattern¶
file: patternlets/MPI/18.reduce+Timing/reduce+timing.c
Build inside 18.reduce+Timing directory:
make reduce+timing
Execute on the command line inside 18.reduce+Timing directory:
mpirun -np <number of processes> ./reduce+timing
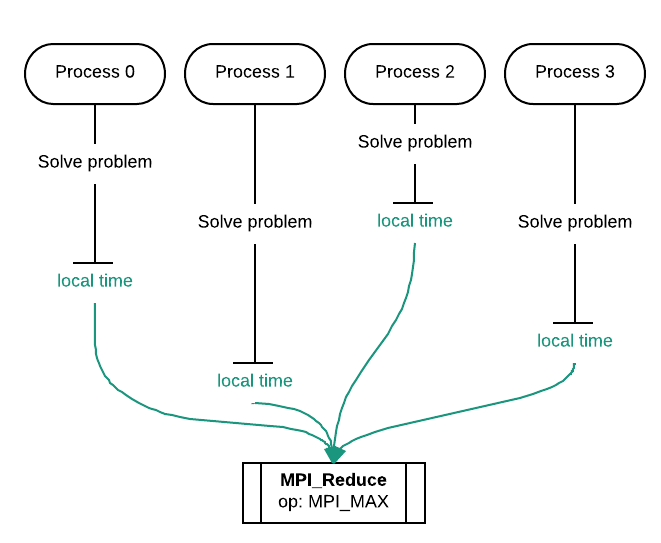
We can also use reduction for obtaining the parallel execution time of a program. In this example, each process individually records how long it took to finish. Each of these local times is then reduced to a single time using the max operator. This allows us to find the largest local time from all processes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | /* reduce+timing.c
* ... illustrates the behavior of MPI_Barrier()
* to coordinate process-timing.
*
* Code by Joel Adams, April 2016
* Modification to include MPI_Reduce() timing,
* Hannah Sonsalla, Macalester College 2017
*
* Usage: mpirun -np 8 ./barrier+timing2
*
* Exercise:
* - Compile; then run the program five times,
* - In a spreadsheet, compute the average,
* median, and minimum of the five times.
* - Explain behavior of MPI_Reduce() in terms
* of localTime and totalTime.
* - Compare results to results from barrier+timing
*/
#include <stdio.h> // printf()
#include <mpi.h> // MPI
#include <unistd.h> // sleep()
#define MASTER 0
/* answer the ultimate question of life, the universe,
* and everything, based on id and numProcs.
* @param: id, an int
* @param: numProcs, an int
* Precondition: id is the MPI rank of this process
* && numProcs is the number of MPI processes.
* Postcondition: The return value is 42.
*/
int solveProblem(int id, int numProcs) {
sleep( ((double)id+1) / numProcs);
return 42;
}
int main(int argc, char** argv) {
int id = -1, numProcesses = -1;
double startTime = 0.0, localTime = 0.0, totalTime = 0.0;
int answer = 0.0;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &id);
MPI_Comm_size(MPI_COMM_WORLD, &numProcesses);
MPI_Barrier(MPI_COMM_WORLD);
startTime = MPI_Wtime();
answer = solveProblem(id, numProcesses);
localTime = MPI_Wtime() - startTime;
MPI_Reduce(&localTime, &totalTime, 1, MPI_DOUBLE,
MPI_MAX, 0, MPI_COMM_WORLD);
if ( id == MASTER ) {
printf("\nThe answer is %d; computing it took %f secs.\n\n",
answer, totalTime);
}
MPI_Finalize();
return 0;
}
|
19. Sequence Numbers¶
file: patternlets/MPI/19.sequenceNumbers/sequenceNumbers.c
Build inside 19.sequenceNumbers directory:
make sequenceNumbers
Execute on the command line inside 19.sequenceNumbers directory:
mpirun -np <number of processes> ./sequenceNumbers
Tags can be placed on messages that are sent from a non-master process and received by the master process. Using tags is an alternative form of simulating the barrier in example 17 above.
To do:
What has caused the changes in the program’s behavior and why has it changed? Can you figure out what the different tags represent and how the tags work in relation to the send and receive functions?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 | /* sequenceNumbers.c
* ... shows how to acheive barrier-like behavior
* by using MPI message tags as sequence numbers.
*
* Joel Adams, Calvin College, April 2016.
*
* Usage: mpirun -np 8 ./sequenceNumbers
*
* Exercise:
* 1. Compile; then run the program several times,
* noting the intermixed outputs
* 2. Comment out the sendReceivePrint(..., "SECOND", 1); call;
* uncomment the sendReceivePrint(..., "SECOND", 2); call;
* then recompile and rerun, noting how the output changes.
* 3. Uncomment the sendReceivePrint(..., "THIRD", 3);
* and sendReceivePrint(..., "FOURTH", 4); calls,
* then recompile and rerun, noting how the output changes.
* 4. Explain the differences: what has caused the changes
* in the program's behavior, and why?
*/
#include <stdio.h> // printf()
#include <mpi.h> // MPI
/* Have workers send messages to the master, which prints them.
* @param: id, an int
* @param: numProcesses, an int
* @param: hostName, a char*
* @param: messageNum, a char*
* @param: tagValue, an int
*
* Precondition: this routine is being called by an MPI process
* && id is the MPI rank of that process
* && numProcesses is the number of processes in the computation
* && hostName points to a char array containing the name of the
* host on which this MPI process is running
* && messageNum is "FIRST", "SECOND", "THIRD", ...
* && tagValue is the value for the tags of the message
* being sent and received this invocation of the function.
*
* Postcondition: each process whose id > 0 has sent a message to process 0
* containing id, numProcesses, hostName, messageNum,
* and tagValue
* && process 0 has received and output each message.
*/
#define BUFFER_SIZE 200
#define MASTER 0
void sendReceivePrint(int id, int numProcesses, char* hostName,
char* messageNum, int tagValue) {
char buffer[BUFFER_SIZE] = {'\0'};;
MPI_Status status;
if (id != MASTER) {
// Worker: Build a message and send it to the Master
int length = sprintf(buffer,
"This is the %s message from process #%d of %d on %s.\n",
messageNum, id, numProcesses, hostName);
MPI_Send(buffer, length+1, MPI_CHAR, 0, tagValue, MPI_COMM_WORLD);
} else {
// Master: Receive and print the messages from all Workers
for(int i = 0; i < numProcesses-1; i++) {
MPI_Recv(buffer, BUFFER_SIZE, MPI_CHAR, MPI_ANY_SOURCE,
tagValue, MPI_COMM_WORLD, &status);
printf("%s", buffer);
}
}
}
int main(int argc, char** argv) {
int id = -1, numProcesses = -1, length = -1;
char myHostName[MPI_MAX_PROCESSOR_NAME] = {'\0'};
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &id);
MPI_Comm_size(MPI_COMM_WORLD, &numProcesses);
MPI_Get_processor_name (myHostName, &length);
sendReceivePrint(id, numProcesses, myHostName, "FIRST", 1);
sendReceivePrint(id, numProcesses, myHostName, "SECOND", 1);
// sendReceivePrint(id, numProcesses, myHostName, "SECOND", 2);
// sendReceivePrint(id, numProcesses, myHostName, "THIRD", 3);
// sendReceivePrint(id, numProcesses, myHostName, "FOURTH", 4);
MPI_Finalize();
return 0;
}
|
