Including CUDA¶
Download Pandemic-MPI-CUDA.zip
In this chapter, we will include CUDA functions into the pandemic program we developed. Since CUDA only takes over the program when we execute the core functions, most of the program remain unchanged. However, following changes are needed for CUDA set up and initialization.
In Defaults.h¶
We need to include one extra structure in the Defualts.h file. This structure will include all the pointers used for GPU device memory and other necessary data, such as CUDA block size and CUDA grid size.
cuda_t struct¶
// All the data needed for CUDA operation: CUDA needs memory
// pointers and other information on CPU side. As more than
// one function (mainly used by CUDA.cu) need to use these
// data, we decided to use a struct to hold all these data.
struct cuda_t
{
// correspond with their_infected_locations in global struct
int *their_infected_x_locations_dev;
int *their_infected_y_locations_dev;
// correspond with our_infected_locations in our struct
int *our_x_locations_dev;
int *our_y_locations_dev;
// correspond with our_states and our_num_days_infected in our struct
int *our_num_days_infected_dev;
char *our_states_dev;
// some counter variables require atomic operations
// correspond with states counters in our struct
int *our_num_susceptible_dev;
int *our_num_immune_dev;
int *our_num_dead_dev;
int *our_num_infected_dev;
// correspond with variables in stats struct
int *our_num_infections_dev;
int *our_num_infection_attempts_dev;
int *our_num_deaths_dev;
int *our_num_recovery_attempts_dev;
// the following four variables serve as the intermediate
// variables. we initialized variables in stats struct as
// doubles, but cuda atomic operations works better for
// int. So we cast doubles to int and then cast them back
int our_num_infections_int;
int our_num_infection_attempts_int;
int our_num_deaths_int;
int our_num_recovery_attempts_int;
// size used by cudaMalloc
int our_size;
int their_size;
int our_states_size;
// size used by cuda kernel calls
int numThread;
int numBlock;
};
their_infected_x_locations_dev
pointer, pointed to the memory location on device of array their_infected_x_locations_dev, a copy of their_infected_x_locations on host memory.
their_infected_y_locations_dev
pointer, pointed to the memory location on device of array their_infected_y_locations_dev, a copy of their_infected_y_locations on host memory.
our_x_locations_dev
pointer, pointed to the memory location on device of array our_x_locations_dev, a copy of our_x_locations on host memory.
our_y_locations_dev
pointer, pointed to the memory location on device of array our_y_locations_dev, a copy of our_y_locations on host memory.
our_num_days_infected_dev
pointer, pointed to the memory location on device of array our_num_days_infected_dev, a copy of our_num_days_infected on host memory.
our_states_dev
pointer, pointed to the memory location on device of array our_states_dev, a copy of our_states on host memory.
our_num_susceptible_dev
pointer, pointed to the memory location on device of counter our_num_susceptible_dev, a copy of our_num_susceptible on host memory.
our_num_immune_dev
pointer, pointed to the memory location on device of counter our_num_immune_dev, a copy of our_num_immune on host memory.
our_num_dead_dev
pointer, pointed to the memory location on device of counter our_num_dead_dev, a copy of our_num_dead on host memory.
our_num_infected_dev
pointer, pointed to the memory location on device of counter our_num_infected_dev, a copy of our_num_infeced on host memory.
our_num_infections_dev
pointer, pointed to the memory location on device of counter our_num_infections_dev, a copy of our_num_infections on host memory.
our_num_infection_attempts_dev
pointer, pointed to the memory location on device of counter our_num_infection_attempts_dev, a copy of our_num_infection_attempts on host memory.
our_num_deaths_dev
pointer, pointed to the memory location on device of counter our_num_deaths_dev, a copy of our_num_deaths on host memory.
our_num_recovery_attempts_dev
pointer, pointed to the memory location on device of counter our_num_recovery_attempts_dev, a copy of our_num_recovery_attempts on host memory.
our_num_infections_int
int, holds temporary instance of our_num_infections when we cast it into a int.
our_num_infection_attempts_int
int, holds temporary instance of our_num_infection_attempts when we cast it into a int.
our_num_deaths_int
int, holds temporary instance of our_num_deaths when we cast it into a int.
our_num_recovery_attempts_int
int, holds temporary instance of our_num_recovery_attempts when we cast it into a int.
our_size
int, holds the size of any integer arrays inside our_t struct.
their_size
int, holds the size of any integer arrays inside global_t struct.
our_states_size
int, holds the size of any char arrays inside our_t struct.
numThread
int, holds the number of threads per block, or block size.
numBlock
int, holds the number of blocks per grid, or grid size.
In Initialize.h¶
Since we are using CUDA, we need to initialize the CUDA runtime environment. To do this, we add another function in the init() function called cuda_init(). Don’t forget to include the cuda structure in the function parameters.
int init (struct global_t *global, struct const_t *constant, struct stats_t *stats,
struct display_t *dpy, struct cuda_t *cuda, int *c, char ***v)
cuda_init(global, cuda);
Further, as we want to keep all the CUDA functions in one file, we put cuda_init() inside CUDA.cu file. Therefore, we need to include this file before we can use any functions inside it.
#include "CUDA.cu" // for cuda_init()
cuda_init()¶
This function will setup the CUDA runtime environment.
Since we are allocating lots of arrays on the CUDA device memory, we first need to find out the size of each array. In total we need six arrays, of which their_infected_x_locations_dev and their_infected_y_locations_dev should be as long as the total_number_of_people, and the rest four arrays should have length as our_number_of_people. Note that of the four arrays above, our_states_dev is different from the rest because it holds char instead of int, which means we have to assign different size to it. The following line sets sizes we want.
// initialize size needed for cudamalloc operations
cuda->our_size = sizeof(int) * our->our_number_of_people;
cuda->their_size = sizeof(int) * global->total_number_of_people;
cuda->our_states_size = sizeof(char) * our->our_number_of_people;
After setting up the sizes, we can allocate arrays on the device. Note that all the pointers are already initialized in the cuda structure.
// arrays in global and our struct
cudaMalloc((void**)&cuda->their_infected_x_locations_dev, cuda->their_size);
cudaMalloc((void**)&cuda->their_infected_y_locations_dev, cuda->their_size);
cudaMalloc((void**)&cuda->our_x_locations_dev, cuda->our_size);
cudaMalloc((void**)&cuda->our_y_locations_dev, cuda->our_size);
cudaMalloc((void**)&cuda->our_states_dev, cuda->our_states_size);
cudaMalloc((void**)&cuda->our_num_days_infected_dev, cuda->our_size);
Besides arrays, we also need in allocate spaces for the eight counters in our structure and stats structure.
// states counters in our struct
cudaMalloc((void**)&cuda->our_num_susceptible_dev, sizeof(int));
cudaMalloc((void**)&cuda->our_num_immune_dev, sizeof(int));
cudaMalloc((void**)&cuda->our_num_dead_dev, sizeof(int));
cudaMalloc((void**)&cuda->our_num_infected_dev, sizeof(int));
#ifdef SHOW_RESULTS
// stats variables in stats struct
cudaMalloc((void**)&cuda->our_num_infections_dev, sizeof(int));
cudaMalloc((void**)&cuda->our_num_infection_attempts_dev, sizeof(int));
cudaMalloc((void**)&cuda->our_num_deaths_dev, sizeof(int));
cudaMalloc((void**)&cuda->our_num_recovery_attempts_dev, sizeof(int));
#endif
After allocating structure, we need to set up the random number generator. Since all the device code are executed on GPU device instead of on CPU, functions like random() will not work. Therefore, we need to use NVIDIA cuRAND library to generate all the random numbers. According to the documentation of cuRAND library, the normal sequence of operations to generate random number for CUDA device can be divided into seven steps. cuda_init() function will cover three steps, cuda_run() function will cover three steps, and cuda_finish() function will cover the last step.
- Create a new generator of the desired type with curandCreateGenerator().
// create cuda random number generator
curandCreateGenerator(&gen, CURAND_RNG_PSEUDO_DEFAULT);
- Set the generator options; for example, use curandSetPseudoRandomGeneratorSeed() to set the seed.
// get time
time(¤t_time);
// generate seed for the rand number generator
curandSetPseudoRandomGeneratorSeed(gen, (unsigned long)current_time);
- Allocate memory on the device with cudaMalloc().
// array to hold random number
cudaMalloc((void**)&rand_nums, 2 * our->our_number_of_people * sizeof(float));
After generating random numbers, we need to set up block size and grid size for CUDA operations. Since the primary data type of our program is array, we can initialize only 1-D array for CUDA device functions.
Since the primary test machine for this module is LittleFe, which features NVIDIA ION Graphics (ION2), we set the block size to be 256 threads per block as the maximum active threads per multiprocessor on ION Graphics (Compute Capability 1.3) is 512. However, if you have GPU cards that are more advanced (Compute Capability 2.0+), you can set the block size to 512, 1024 or even 2048.
cuda->numThread = (our->our_number_of_people < 256 ? our->our_number_of_people : 256);
Further, if we have less than 256 people in our simulation, we initialize exactly number of people many of threads.
As for grid size, we decide grid size according to our simulation size. For example, if you have 1000 people in your simulation, program will initialize 4 blocks.
cuda->numBlock = (our->our_number_of_people+cuda->numThread-1)/cuda->numThread;
Replace file Core.h with file CUDA.cu¶
CUDA Global Variable¶
At any time, use of global variables outside of main() function is discouraged in C programming, mainly because it is really difficult to handle the scope of the program. However, as we are building a CUDA and MPI hybrid, all CUDA code need to be compiled with nvcc compiler, which means we need to separate CUDA code from other code. Normally, we should declare these variables inside cuda_t structure we initialized in main() function, but the problem is that MPI compiler mpicc or C compiler gcc or icc does not recognize the type curandGenerator_t, which forces us to declare global variable inside this file, which will eventually compiled by nvcc.
gen
curandGenerator_t, which is effectively a random generator on CUDA device. A generator in CURAND encapsulates all the internal state necessary to produce a sequence of pseudorandom or quasirandom numbers.
current_time
time_t, variable we use to hold the current time. We will use this as seed.
rand_nums
array, this is a pointer pointed to an array of random float numbers.
CUDA Device Functions¶
Inside Core.h file, we have four core functions for our pandemic simulation. move(), susceptible(), infected() and update_days_infected. Inside CUDA.cu file, we implemented those four functions with CUDA architecture.
cuda_move()¶
This is a CUDA implementation of the move() function in core functions chapter.
First, each thread randomly picks whether the person moves left or right or does not move in the x dimension.
// The thread randomly picks whether the person moves left
// or right or does not move in the x dimension
int x_move_direction = (int)(rand_nums[id]*3) - 1;
The code uses (int)(rand_nums[id]*3) - 1; to achieve this. rand_num is a array of random numbers generated before. All the random numbers in this array are floats between 0 and 1. Then, rand_nums[id]*3 will turn all the floats to numbers between 0 and 3. After this, we can cast all the floats to int, which eventually will make all the numbers as either 0, 1 or 2. Finally, we subtract 1 from this to produce -1, 0, or 1. This means the person can move to the right(1), stay in place (0), or move to the left (-1).
The thread randomly picks whether the person moves up or down or does not move in the y dimension. This is similar to movement in x dimension.
// The thread randomly picks whether the person moves up
// or down or does not move in the y dimension
int y_move_direction = (int)(rand_nums[id+SIZE]*3) - 1;
Next, we need to make sure the person remain in the bounds of the environment after moving. We check this by making sure the person’s x location is greater than or equal to 0 and less than the width of the environment and that the person’s y location is greater than or equal to 0 and less than the height of the environment. In the code, it looks like this:
if( (x_locations_dev[id] + x_move_direction >= 0) &&
(x_locations_dev[id] + x_move_direction < environment_width) &&
(y_locations_dev[id] + y_move_direction >= 0) &&
(y_locations_dev[id] + y_move_direction < environment_height) )
Finally, The thread moves the person
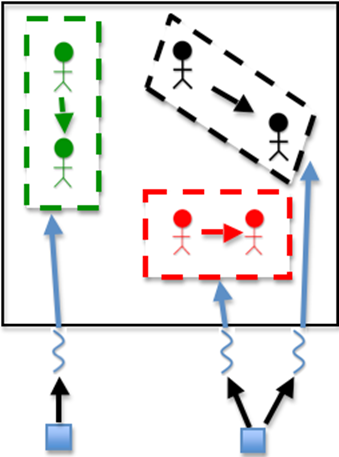
// The thread moves the person
x_locations_dev[id] = x_locations_dev[id] + x_move_direction;
y_locations_dev[id] = y_locations_dev[id] + y_move_direction;
cuda_susceptible()¶
This is a CUDA implementation of the susceptible() function in core functions chapter.
If the person is susceptible,
if(states_dev[id] == SUSCEPTIBLE)
For each of the infected people (received earlier from all processes) or until the number of infected people nearby is 1,
for(i=0; i<=global_num_infected-1 && num_infected_nearby<1; i++)
If this person is within the infection radius,
if( (x_locations_dev[id] > infected_x_locations_dev[i] - infection_radius) &&
(x_locations_dev[id] < infected_x_locations_dev[i] + infection_radius) &&
(y_locations_dev[id] > infected_y_locations_dev[i] - infection_radius) &&
(y_locations_dev[id] < infected_y_locations_dev[i] + infection_radius) )
then, the thread increments the number of infected people nearby
num_infected_nearby++;
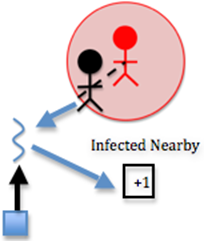
This is where a large chunk of the algorithm’s computation occurs. Each susceptible person must be computed with each infected person to determine how many infected people are nearby each person. Two nested loops means many computations. In this step, the computation is fairly simple, however. The thread simply increments the num_infected_nearby variable.
Note in the code that if the number of infected nearby is greater than or equal to 1 and we have SHOW_RESULTS enabled, we increment the num_infection_attempts variable. This helps us keep track of the number of attempted infections, which will help us calculate the actual contagiousness of the disease at the end of the simulation.
Similar to cuda_move(), we also need random numbers in this function. The difference is that we need integers between -1 and 1 in cuda_move() function but we need integers between 0 and 100 in this function. We obtain this random number using
// generate a random number between 0 and 100
int rand_num = (int)(rand_nums[id]*100);
where rand_nums is still an array of random floats between 0 and 1 and we can multiply it with 100 and cast it into a int.
If there is at least one infected person nearby, and a random number less than 100 is less than or equal to the contagiousness factor, then
if(num_infected_nearby >= 1 && rand_num <= contagiousness_factor)
The thread changes person’s state to infected
states_dev[id] = INFECTED;
So far the code is similar to the susceptible() function executed on the CPU end. However, things get trickier from here. Since every threads need to update counters like num_infected or num_susceptible if someone is infected, we have racing conditions. In order to handle racing conditions and to maximize performance at the same time, we use both cuda shared memory and cuda atomic operations to update counters.
We use shared memory as temporary arrays to holds counters changed by each thread, then we would reduce this array to a single number. Finally, we use CUDA atomic operations to add the number back to actual counter.
CUDA shared memory is cache assigned to each multiprocessor. In case some of you are not familiar with the concept of multiprocessor, you can think of multiprocessor is the physical phase of blocks in CUDA coding. A typical NVIDIA GPU card with Fermi architecture (perfectly fine if you don’t know what this is) supports maximum 1024 active threads per multiprocessor. This means that you can run 1024 threads concurrently on each multiprocessor. The reason we usually chose 128, 256 or 512 threads per block is that we want each multiprocessor can host exactly 8, 4 or 2 blocks on it.
However, even if we use 128 threads per block when we launch the device functions, we don’t necessarily get 8 blocks per multiprocessor. Why? Because each multiprocessor has limited shared memory and registers available. GPU with Fermi architecture usually have 48KB of shared memory per multiprocessor, which means that if each block uses 8KB of shared memory, you can only initialize 6 blocks on each multiprocessor. For us, this is less of a concern because we only allocate four or five (later you will see why is four or five) arrays per block. Even we are using 1024 threads per block, we need maximum 5 * 1024 * sizeof(int) = 20KB, which is less than half of the shared memory available.
We first need to find out how many counters need atomic operations, in this function, there are four of them: num_infected_dev, num_susceptible_dev, num_infection_attempts_dev and num_infections_dev. This is important because we need to allocate enough memory when we invoke the device function calls. Since we have four counters need atomic operations, we need to allocate four arrays, each having the length of the numbers of threads per block. The following line declares the shared memory:
/* CUDA shared memory allocation */
extern __shared__ int array[];
This line suggests that we allocated an array of the data type int. However, it does not specify how long the array should be. Then, inside cuda_susceptible function, the following lines set up the four arrays we use for reduction.
// set up shared memory
int *num_infected = (int*)array;
int *num_susceptible = (int*)&num_infected[numThread];
#ifdef SHOW_RESULTS
int *num_infection_attempts = (int*)&num_susceptible[numThread];
int *num_infections = (int*)&num_infection_attempts[numThread];
#endif
we set the pointer of the first array as the pointer of the shared memory array. Then, we set the pointer of the second array as the pointer exactly numThread away from the pointer of the first array. We are essentially dividing the initial shared memory array into four equal sized arrays.
After shared memory setup, we need to reset the shared memory. So each thread set its corresponding shared memory elements to zero at the very beginning of the function.
// reset the shared memory
num_infected[blockId] = 0;
num_susceptible[blockId] = 0;
#ifdef SHOW_RESULTS
num_infection_attempts[blockId] = 0;
num_infections[blockId] = 0;
#endif
Again this is very important. Shared memory will not clear itself after usage, and failing to clear shared memory before usage usually meaning you are starting from what ever values the shared memory is left with from last CUDA operations.
When we are updating counters, instead of adding one to or subtracting one from the actual counter located on GPU device, in this case the num_infected_dev or num_susceptible_devcounter, we add one to or subtract one from the thread’s corresponding array elements.
#ifdef SHOW_RESULTS
num_infection_attempts[blockId]++;
#endif
num_infected[blockId]++;
num_susceptible[blockId]--;
#ifdef SHOW_RESULTS
num_infections[blockId]++;
#endif
Finally, we need to add up the values in each array to obtain the final result. We do this using CUDA binary tree reduction. This is the official way to perform reduction operations in CUDA. The basic idea is that you create a half point on the array, use the first half thread to add the values of second half thread. This means that the array shrinks to one half of its original size. Then you can do another reduction, which will shrinks the array to one fourth of its original size. When the operation is done, the correct sum is stored at the first element of the array.The following is the implementation:
i = numThread/2;
while (i != 0) {
if (blockId < i){
num_infected[blockId] += num_infected[blockId + i];
num_susceptible[blockId] += num_susceptible[blockId + i];
#ifdef SHOW_RESULTS
num_infection_attempts[blockId] += num_infection_attempts[blockId + i];
num_infections[blockId] += num_infections[blockId + i];
#endif
}
__syncthreads();
i /= 2;
}
As you probably already see, one limitation of this operation is that the array size has to be the power of 2, which essentially meaning that the block size should be power of 2 as well. If we are dealing with problem size as large as tens of thousands even millions, this won’t hurt us because we are always initializing 128, 256, 512 or even 1024 threads per block. However, if we are dealing with problem size as small as 50, things gets a little bit tricker.
Therefore, we put a if statement that checks whether the size of the block is power of 2 before we do any reduction operations. Such as:
if(((numThread!=0) && !(numThread & (numThread-1)))){
if we indeed do not have some power of 2 many of threads in a block, we can use the first thread of the block to add all other entries in the array to the first element.
if(blockId == 0) {
for(i=1; i<numThread; i++){
num_infected[0] += num_infected[i];
num_susceptible[0] += num_susceptible[i];
#ifdef SHOW_RESULTS
num_infection_attempts[0] += num_infection_attempts[i];
num_infections[0] += num_infections[i];
#endif
}
}
The good news is that when we run into this problem, normally means that we are dealing with a very small problem size, which should not affect the performance significantly. Notice that we could use the first thread to add up the values even if we have 128 or 256 threads per block, but the reduction takes 127 or 255 steps. However, the binary tree reduction takes 7 or 8 steps to do the same. This will make our program run much faster.
Finally, the first thread update the acutal counter with the first value of the array. However, we still face racing condition because more than one block could be updating the actual counter at the same time. CUDA designs functions like atomicAdd to handle situations like this, it can slow down your program significantly if you use atomicAdd too much, but since we are doing this once per block per counter, we do not suffer too much from performance loss.
if(blockId == 0) {
atomicAdd(num_infected_dev, num_infected[0]);
atomicAdd(num_susceptible_dev, num_susceptible[0]);
#ifdef SHOW_RESULTS
atomicAdd(num_infection_attempts_dev, num_infection_attempts[0]);
atomicAdd(num_infections_dev, num_infections[0]);
#endif
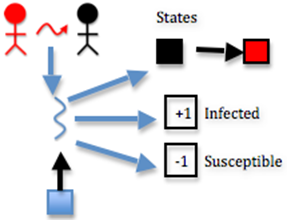
Note in the code that if the infection succeeds and we have SHOW_RESULTS enabled, we increment the num_infections_dev variable. This helps us keep track of the actual number of infections, which will help us calculate the actual contagiousness of the disease at the end of the simulation.
cuda_infected()¶
This is a CUDA implementation of the infected() function in core functions chapter.
If the person is infected and has been for the full duration of the disease, then
if(states_dev[id] == INFECTED && num_days_infected_dev[id] == duration_of_disease)
Note in the code that if we have SHOW_RESULTS enabled, we increment the num_recovery_attempts_dev variable. This helps us keep track of the number of attempted recoveries, which will help us calculate the actual deadliness of the disease at the end of the simulation.
#ifdef SHOW_RESULTS
num_recovery_attempts[blockId]++;
#endif
After this, if a random number less than 100 is less than the deadliness factor, then
// generate a random number between 0 and 100
int rand_num = (int)(rand_nums[id]*100);
The thread changes the person’s state to dead
// The thread changes the person’s state to dead
states_dev[id] = DEAD;
and then the thread updates the counters
// The thread updates the counters
num_dead[blockId]++;
num_infected[blockId]--;
#ifdef SHOW_RESULTS
num_deaths[blockId]++;
#endif
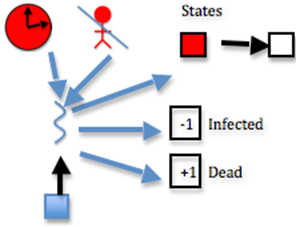
This step is effectively the same as function susceptible, considering deadliness instead of contagiousness. The difference here is the following step:
if a random number less than 100 is less than the deadliness factor, the thread changes the person’s state to immune
// The thread changes the person’s state to immune
states_dev[id] = IMMUNE;
and then thread updates the counters
// The thread updates the counters
num_immune[blockId]++;
num_infected[blockId]--;
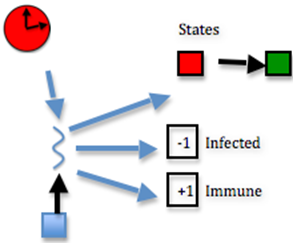
If deadliness fails, then immunity succeeds.
Note in the code that if the person dies and we have SHOW_RESULTS enabled, we increment the num_deaths_dev variable. This helps us keep track of the actual number of deaths, which will help us calculate the actual deadliness of the disease at the end of the simulation.
Note that the reduction process is the same as the susceptible_cuda() function, which involves shared memory reduction and CUDA atomic operations. The only difference is that we have five counters to reduce instead of four. This will be reflected when we assign shared memory space for each block.
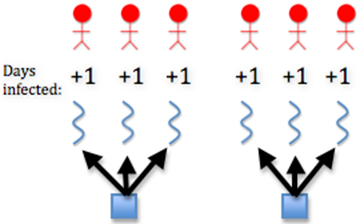
cuda_update_days_infected()¶
This is the CUDA implementation of the update_days_infected() function in core functions chapter.
If the person is infected, then
if(states_dev[id] == INFECTED)
Increment the number of days the person has been infected
// Increment the number of days the person has been infected
num_days_infected_dev[id]++;
Change function calls in Pandemic.c File¶
Since we are not using core functions in Core.h file and we are using device functions on CUDA device, we need to change function calls in main() function.
Before changing function calls, we first need to include Cuda.cu file before we can use any of the functions in it.
#include "Infection.h"
#include "CUDA.cu"
#include "Finalize.h"
Then we need to create a cuda structure.
struct cuda_t cuda;
Finally, we replace the four core function calls with a single function call. Why only one function call? Because calling a CUDA function is more complicated than calling a normal function, and we want to keep all the CUDA code together in the same file. Therefore, we created a cuda_run() function.
cuda_run()¶
This function will execute the CUDA device functions.
We first use cudaMemcpy() to copy data on host memory to GPU device memory. Since all of the code only performs one day’s simulation, we need to put cuda_run() function inside a loop. One could call all the cudaMemcpy() functions in each iteration, or we could divide them into two categories, those that requires constantly communicating with CPU and those who do not.
After careful examination of the code, it is not hard to find out that some functions, especially MPI functions, on host end need infected_x_locations and infected_y_locations to share infected information to all other nodes. They also need these arrays to do display. Therefore, in every iteration, we need to copy these two arrays to GPU device and copy then back to host after execution. However, other arrays or counters can reside on card from start to finish without re-copy from host to GPU device. Therefore, we implement cudaMemcpy() functions in the following fashion,
// copy infected locations to device in EVERY ITERATION
cudaMemcpy(cuda->their_infected_x_locations_dev, global->their_infected_x_locations, cuda->their_size, cudaMemcpyHostToDevice);
cudaMemcpy(cuda->their_infected_y_locations_dev, global->their_infected_y_locations, cuda->their_size, cudaMemcpyHostToDevice);
// copy other information to device only in FIRST ITERATION
// we don't need to copy these information every iteration
// becuase they can be reused in each iteration without any
// process at the host end.
if(our->current_day == 0){
// copy arrays in our struct
cudaMemcpy(cuda->our_x_locations_dev, our->our_x_locations, cuda->our_size, cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_y_locations_dev, our->our_y_locations, cuda->our_size, cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_states_dev, our->our_states, cuda->our_states_size, cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_num_days_infected_dev, our->our_num_days_infected, cuda->our_size, cudaMemcpyHostToDevice);
// copy states counters in our struct
cudaMemcpy(cuda->our_num_susceptible_dev, &our->our_num_susceptible, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_num_immune_dev, &our->our_num_immune, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_num_dead_dev, &our->our_num_dead, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_num_infected_dev, &our->our_num_infected, sizeof(int), cudaMemcpyHostToDevice);
#ifdef SHOW_RESULTS
// variables in stats data are initialized as doubles, yet CUDA
// atomic operations prefer integer than doubles. Therefore, we
// cast doubles to integer before the cudaMemcpy operations.
cuda->our_num_infections_int = (int)stats->our_num_infections;
cuda->our_num_infection_attempts_int = (int)stats->our_num_infection_attempts;
cuda->our_num_deaths_int = (int)stats->our_num_deaths;
cuda->our_num_recovery_attempts_int = (int)stats->our_num_recovery_attempts;
// copy stats variables in stats struct
cudaMemcpy(cuda->our_num_infections_dev, &cuda->our_num_infections_int, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_num_infection_attempts_dev, &cuda->our_num_infection_attempts_int, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_num_deaths_dev, &cuda->our_num_deaths_int, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(cuda->our_num_recovery_attempts_dev, &cuda->our_num_recovery_attempts_int, sizeof(int), cudaMemcpyHostToDevice);
#endif
}
where if(our->current_day == 0) makes sure that most of the data only gets copied in the first iteration, instead of in every iteration.
Another thing you probably noticed is that we cast stats counters to int before sending them to the GPU device memory.
cuda->our_num_infections_int = (int)stats->our_num_infections;
cuda->our_num_infection_attempts_int = (int)stats->our_num_infection_attempts;
cuda->our_num_deaths_int = (int)stats->our_num_deaths;
cuda->our_num_recovery_attempts_int = (int)stats->our_num_recovery_attempts;
This is because that variables in stats structure are initialized as doubles, but CUDA atomic operations prefer integer. Since we always perform integer operations on stats counters (either add one or subtract one), we can first cast them into int, and we can later cast them back to double after device function’s execution.
After the copying the data, we need to generate the random numbers. Recall that we performed the first three steps of the seven steps CUDA random number generation process, the next step, or the fourth step is:
- Generate random numbers with curandGenerate() or another generation function.
curandGenerateUniform(gen, rand_nums, 2 * our->our_number_of_people);
Notice that we are generating twice many of total people number of random numbers. This is because the next device function call is cuda_move(), which moves every person in both x direction and y direction.
Then, we can call device functions from host:
// execute device code on updating people's movement
int environment_width = constant->environment_width;
int environment_height = constant->environment_height;
cuda_move<<<cuda->numBlock, cuda->numThread>>>(cuda->our_states_dev,
cuda->our_x_locations_dev, cuda->our_y_locations_dev, DEAD,
environment_width, environment_height, rand_nums, our->our_number_of_people);
// Sync Threads
cudaThreadSynchronize();
// generate our_number_of_people many of randome numbers.
curandGenerateUniform(gen, rand_nums, our->our_number_of_people);
// execute device code on susceptible people
int infection_radius = constant->infection_radius;
int contagiousness_factor = constant->contagiousness_factor;
int total_num_infected = global->total_num_infected;
cuda_susceptible<<<cuda->numBlock, cuda->numThread, 4*cuda->numThread*sizeof(int)>>>(
cuda->our_states_dev, cuda->our_x_locations_dev, cuda->our_y_locations_dev,
cuda->their_infected_x_locations_dev, cuda->their_infected_y_locations_dev,
cuda->our_num_infected_dev, cuda->our_num_susceptible_dev,
cuda->our_num_infection_attempts_dev, cuda->our_num_infections_dev,
rand_nums, total_num_infected, infection_radius,
contagiousness_factor, SUSCEPTIBLE, INFECTED);
// Sync Threads
cudaThreadSynchronize();
// generate our_number_of_people many of randome numbers.
curandGenerateUniform(gen, rand_nums, our->our_number_of_people);
// execute device code on infected people
int duration_of_disease = constant->duration_of_disease;
int deadliness_factor = constant->deadliness_factor;
cuda_infected<<<cuda->numBlock, cuda->numThread, 5*cuda->numThread*sizeof(int)>>>(
cuda->our_states_dev, cuda->our_num_days_infected_dev,
cuda->our_num_recovery_attempts_dev, cuda->our_num_deaths_dev,
cuda->our_num_infected_dev, cuda->our_num_immune_dev,
cuda->our_num_dead_dev, duration_of_disease, deadliness_factor,
IMMUNE, DEAD, INFECTED, rand_nums);
// Sync Threads
cudaThreadSynchronize();
// execute device code to update infected days
cuda_update_days_infected<<<cuda->numBlock, cuda->numThread>>>(
cuda->our_states_dev, cuda->our_num_days_infected_dev, INFECTED);
// Sync Threads
cudaThreadSynchronize();
Most of the device function calls are straight forward, however, two things needed to be pointed out. First is that we perform the 5th step and 6th step of CUDA random number generation process in between, which are
- Use the results.
- If desired, generate more random numbers with more calls to curandGenerate().
Another thing is that when calling cuda_susceptible() and cuda_infected() functions, we passed a third argument other than numThread and numBlock to device function.
cuda_susceptible<<<cuda->numBlock, cuda->numThread, 4*cuda->numThread*sizeof(int)>>>(
cuda_infected<<<cuda->numBlock, cuda->numThread, 5*cuda->numThread*sizeof(int)>>>(
The third parameter is the size of the shared memory, which depends on how many counters we need to reduce in each function.
Finally, we need to copy GPU device data back to host. However, just like when we copy data from host to GPU device, we need to differentiate data that needs to be copied in every iteration and those that needs to be copied only once. In this case, we need to copy arrays x_locations, y_locations and states back to host memory. This is because MPI functions will need them to perform Allgather() and Allgatherv() operations. We also copied counter num_infected back because we need it in other functions as well.
As for other arrays or counters, we can copy them back in the last iteration. Notice that we never copy num_infected_days array back to host memory, this is because non of the host functions need this array.
// copy our locations, our states and our_num_infected back to host
// in EVERY ITERATION
cudaMemcpy(our->our_x_locations, cuda->our_x_locations_dev, cuda->our_size, cudaMemcpyDeviceToHost);
cudaMemcpy(our->our_y_locations, cuda->our_y_locations_dev, cuda->our_size, cudaMemcpyDeviceToHost);
cudaMemcpy(our->our_states, cuda->our_states_dev, cuda->our_states_size, cudaMemcpyDeviceToHost);
cudaMemcpy(&our->our_num_infected, cuda->our_num_infected_dev, sizeof(int), cudaMemcpyDeviceToHost);
// copy other information back to host only in LAST ITERATION
// we only copy the counters back for results calculation.
// we don't need to copy our_num_days_infected back.
if(our->current_day == constant->total_number_of_days){
// copy states counters in our struct
cudaMemcpy(&our->our_num_susceptible, cuda->our_num_susceptible_dev, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&our->our_num_immune, cuda->our_num_immune_dev, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&our->our_num_dead, cuda->our_num_dead_dev, sizeof(int), cudaMemcpyDeviceToHost);
#ifdef SHOW_RESULTS
// copy stats variables in stats struct
cudaMemcpy(&cuda->our_num_infections_int, cuda->our_num_infections_dev, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&cuda->our_num_infection_attempts_int, cuda->our_num_infection_attempts_dev, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&cuda->our_num_deaths_int, cuda->our_num_deaths_dev, sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy(&cuda->our_num_recovery_attempts_int, cuda->our_num_recovery_attempts_dev, sizeof(int), cudaMemcpyDeviceToHost);
// cast interger back to double after the cudaMemcpy operations.
stats->our_num_infections = (double)cuda->our_num_infections_int;
stats->our_num_infection_attempts = (double)cuda->our_num_infection_attempts_int;
stats->our_num_deaths = (double)cuda->our_num_deaths_int;
stats->our_num_recovery_attempts = (double)cuda->our_num_recovery_attempts_int;
#endif
}
In Finalize.h¶
After the CUDA operations, we need to perform clean up operations, such as free memory allocated on device and destroy random number generator. All these operations are packed in the cuda_finish() function in the CUDA.cu file. However, we still need to call this function from somewhere. We decided to call this function inside cleanup() function in Finalize.h file.
Just like modifying Initialize.h, we first need to include CUDA.cu file,
#include "CUDA.cu" // for cuda_finish()
Then we can call the cuda_finish() function
cuda_finish(cuda);
cuda_finish()¶
This function will finish the CUDA environment.
After allocating all the arrays and counters on GPU device memory, we need to free them.
// free the memory on the GPU
// arrays in global and our struct
cudaFree(cuda->their_infected_x_locations_dev);
cudaFree(cuda->their_infected_y_locations_dev);
cudaFree(cuda->our_x_locations_dev);
cudaFree(cuda->our_y_locations_dev);
cudaFree(cuda->our_states_dev);
cudaFree(cuda->our_num_days_infected_dev);
// states counters in our struct
cudaFree(cuda->our_num_susceptible_dev);
cudaFree(cuda->our_num_immune_dev);
cudaFree(cuda->our_num_dead_dev);
cudaFree(cuda->our_num_infected_dev);
#ifdef SHOW_RESULTS
// stats variables in stats struct
cudaFree(cuda->our_num_infections_dev);
cudaFree(cuda->our_num_infection_attempts_dev);
cudaFree(cuda->our_num_deaths_dev);
cudaFree(cuda->our_num_recovery_attempts_dev);
#endif
Further, the last step of CUDA random number generation process is:
- Clean up with curandDestroyGenerator().
// array to hold random number
cudaFree(rand_nums);
// destroy cuda random number generator
curandDestroyGenerator(gen);
