Timing and Performance on Multicore machines¶
Timing performance¶
We would like to know how long it takes to run various versions of our programs so that we can determine if adding additional threads to our computation is worth it.
There are several different ways that we can obtain the time it takes a program to run (we typically like to get this time in milliseconds or less).
Simple, less accurate way: linux time program¶
We can obtain the running time for an entire program using the time Linux program. For example, the line
/usr/bin/time -p trap-omp
might display the following output:
OMP defined, threadct = 1
With n = 1048576 trapezoids, our estimate of the integral from 0 to 3.14159 is 2
real 0.04
user 0.04
sys 0.00
Here, we use the full path /usr/bin/time to insure that we are accessing the time program instead of a shell built-in command.
The real time measures actual time elapsed during the running of your command trap-omp. user measures the amount of time executing user code, and sys measures the time executing in Linux kernel code.
To Do
Try the time command using your linux machine, and compare the results for different thread counts. You should find that real time decreases somewhat when changing from 1 thread to 2 threads; user time increases somewhat. Can you think of reasons that might produce these results?
Also, real time and user time increase considerably on some machines when increasing from 2 to 3 or more threads. What might explain that?
Additional accuracy: Using OpenMP functions for timing code¶
The for loop in your trap-omp.C code represents the parallel portion of the code. The other parts are the ‘sequential parts’ where one thread is being used (these portions of code are quite small in this simple example). Using functions to get current time at points in your program, you can begin to examine how long the sequential port takes in relation to the parallel portion. You can also use these functions around all the code to determine how long it takes with varying numbers of processors.
We can use an OMP library function whose ‘signature’ looks like this:
#include <omp.h>
double omp_get_wtime( void );
We can use this in the code in the following way:
// Starting the time measurement
double start = omp_get_wtime();
// Computations to be measured
...
// Measuring the elapsed time
double end = omp_get_wtime();
// Time calculation (in seconds)
double time1 = end - start;
//print out the resulting elapsed time
cout << "Time for paralel computation section: "<< time1 << " seconds." << endl;
...
To Do
Try inserting these pieces code and printing out the time it takes to execute portions of your trap-omp.C code. You will use this for later portions of this activity. You can do this on your local linux machine now to test it out and make sure it is working.
Basic C/C++ timing functions¶
You could use basic linux/C/C++ timing functions: See the end of this activity for an explanation of the way in which we can time any C/C++ code, even if you are not using OpenMP library functions or pragmas. This will come in handy in cases where you are not using OpenMP (such as CUDA, for example).
Using the MTL¶
If you have access to Intel’s Manycore Testing Lab (MTL), you can try some experimenting. You may also use another machine that your instructor will give you access to.
Let’s try using many more threads and really experiment with multicore programming! You will need to use a ‘terminal’ on Macs or ‘Putty’ on PCs. If you are off campus, you will need to ssh into a machine on your campus before then logging into the MTL machine at Intel’s headquarters in Oregon.
Note
Macalester’s machine that you can use is nuggle.macalester.edu.
You can login to the MTL computer, as follows
ssh accountname@207.108.8.131
Use one of the special MTL student account usernames provided to you, together with the password distributed to the class.
Next, copy your program from your laptop or local linux machine to the MTL machine. One way to do this is to use another window (to keep for copying your code), then enter the following command from the directory where your code is located:
scp trap-omp.C accountname@207.108.8.131:
After making this copy, login into the MTL machine 192.55.51.81 in another window.
On the MTL machine, compile and test run your program.
g++ -o trap-omp trap-omp.C -lm -fopenmp
./trap-omp
./trap-omp 2
./trap-omp 16
Note: Since the current directory . may not be in your default path, you probably need to use the path name ./trap-omp to invoke your program.
Now, try some time trials of your code on the MTL machine. (The full pathname for time and the -p flag are unnecessary.) For example, using time:
time trap-omp
time trap-omp 2
time trap-omp 3
time trap-omp 4
time trap-omp 8
time trap-omp 16
time trap-omp 32
What patterns do you notice with the real and user times of various runs of trap-omp with various values of threadct?
Also try it without using the time command on the command line and instead using the OpenMP omp_get_wtime() function calls in your code.
To Do
It may be useful to change our problems size, n, to see how this affects the time and to observe the range of times that can occur for various problem sizes. We therefore should eliminate ‘hard coding’ of n.
Now update your code so that you submit the number of elements to compute as an additional command-line argument. Now the number of trapezoids, n should be set to the value in argv[2] (at the time that you set threadcnt to the value in argv[1]). This also involves moving the declaration and assignment of the variable h, also. The updated segment of code should look like this:
/* parse command-line arg for number of threads, n */
if (argc == 2) {
threadct = atoi(argv[1]);
} else if (argc == 3) {
threadct = atoi(argv[1]);
n = atoi(argv[2]);
}
double h = (b - a) / n; /* width of subdivision */
Note
The best way to work is to change your code on your local campus machine and copy it to the MTL using scp. That way you have your own copy.
Submitting Batch Jobs for Timing Accurately¶
To submit a job on MTL and guarantee that you have exclusive access to a nod for timing purposes, you submit your job to a queuing system. You do this by creating a ‘script’ file that will be read by the queuing system. Then you use the qsub command to run that script. Here is an example of the contents of a script file (save it as submit.sh on your MTL account):
#!/bin/sh
#PBS -N LS\_trap
#PBS -j oe
#here is how we can send parameters from job submission on the command
line:
$HOME/240activities/trap-omp $p $n
# this is a shell script comment
# the job gets submitted like this:
# qsub -l select=1:ncpus=32 -v 'p=32, n=10485760'
/home/mcls/240activities/submit.sh
######### end of script file
Here is an example of how you run the script (change the path for your user account):
qsub -l select=1:ncpus=32 -v 'p=32, n=10485760'
/home/mcls/240activities/submit.sh
Investigating ‘scalability’¶
Scalability is the ability of a parallel program to run increasingly larger problems. In our simple program, the problem size is the number of trapazoids whose area are computed. You will now conduct some investigations of two types of scalability of parallel programs:
- stong scalability
- weak scalbility
Strong Scalability¶
As you keep the same ‘problem size’, i.e. the amount of work being done,
and increase the number of processors, you would hope that the time
drops proportionally to the number of processors used. So in your case
of the problem size being the number of trapezoids computed, 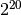 , are
you able to halve the time as you double the number of threads? When
does this stop being the case, if at all? When this occurs, your
program is exhibiting strong scalability, in that additional resources
(threads in this case) help you obtain an answer faster. To truly
determine whether you have strong scalability, you will likely need to
try a larger problem size on the MTL.
, are
you able to halve the time as you double the number of threads? When
does this stop being the case, if at all? When this occurs, your
program is exhibiting strong scalability, in that additional resources
(threads in this case) help you obtain an answer faster. To truly
determine whether you have strong scalability, you will likely need to
try a larger problem size on the MTL.
Weak Scalability¶
Another interesting set of experiments to try is to both increase the problem size
by changing the number of trapezoids to values higher than and to correspondingly increase the number of threads. Try
this: if you double the problem size and double the number of threads,
does the loop take the same amount of time? In high performance
computation, this is known as weak scalability: you can keep using more
processors (to a point) to tackle larger problems.
Note
Don’t try more than the maximum 40 cores on the MTL for the above tests.
What happens when you have more threads than cores?¶
Another interesting investigation is to consider what happens when you ‘oversubscribe’ the cores by using more threads than cores available. Try this experiment and write down your results and try to explain them.
An Alternative Method for Timing Code (optional; for reference)¶
The following code snippets can be used in your program to time sections of your program. This is the traditional linux/C/C++ method, which is most likely what the implementation of the OMP function get_wtime() is using.
/* Put this line at the top of the file: */
#include <sys/time.h>
/* Put this right before the code you want to time: */
struct timeval timer_start, timer\_end;
gettimeofday(&timer_start, NULL);
/* Put this right after the code you want to time: */
gettimeofday(&timer_end, NULL);
double time_spent = timer_end.tv_sec - timer_start.tv_sec +
(timer_end.tv_usec - timer_start.tv_usec) / 1000000.0;
printf("Time spent: %.6f\\n", time_spent);
Note
This example uses C printf statements; feel free to use C++ cout syntax, perhaps like this:
cout << "Time for paralel computation section: "<< time_spent << " milliseconds." << endl;
