Using Parallelism to Analyze Very Large Files: Google’s Map Reduce Paradigm¶
Introduction¶
Up to now in this course, you have been writing programs that run sequentially by executing one step at a time until they complete (unless you mistakenly wrote one with an infinite loop!). Sequential execution is the standard basic mode of operation on all computers. However, when we need to process large amounts of data that might take a long time to complete, we can use a technique known as parallel computing, in which we define portions of our computation to run at the same time by using multiple processors on a single machine or multiple computers at the same time.
In a lab and homework in this course you will use a system called MapReduce that was designed to harness the power of many computers together in a cluster to execute in parallel to process large amounts of data. You will be writing programs designed to run in parallel, or concurrently (at the same time), each one working on a portion of the data. By doing this, your parallel program will be faster than a corresponding sequential version using one computer to process all of the data. We call this kind of program one that uses data parallelism, because the data is split and processed in parallel.
MapReduce is a strategy for solving problems using two stages for processing data that includes a sort action between those two stages. This problem-solving strategy has been used for decades in functional programming languages such as LISP or Scheme. More recently Google has adapted the map-reduce programming model (Dean and Ghemawat,2004) to function efficiently on large clusters of computers to process vast amounts of data–for example, Google’s selection of the entire web.
The Apache Foundation provides an open-source implementation of MapReduce for clusters called Hadoop, which has primarily been implemented by Yahoo!. Student researchers at St. Olaf College have created a user interface called WebMapReduce (WMR) that uses Hadoop to make map-reduce programming convenient enough for students in computer science courses to use.
Description of the MapReduce programming model¶
In map-reduce programming, a programmer provides two functions, called the mapper and the reducer, for carrying out a sequence of two computational stages on potentially vast quantities of data. A series of identical ‘map’ functions can be run on a large amount of input data in parallel, as shown in Figure 1. The results from these mapper processes, spread across many computers, are then sent to reduce functions, also spread across many computers. The most important concepts to remember are these:
- The mapper function that you design is applied to each line of data, and breaks up that data into labelled units of interest, called key-value pairs.
- The reducer function that you design is then applied to all the key-value pairs that share the same key, allowing some kind of consolidation of those pairs.
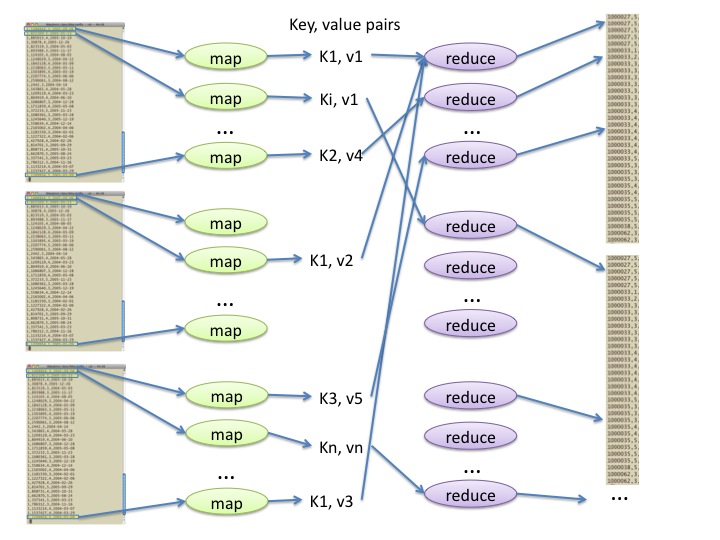
Figure 1: The concept behind how map functions can run in parallel and pass their results to reduce functions, whose results are output in sorted order by the keys created by the reduce function.
In a map-reduce system, which is made of of many computers working at the same time, some computers are assigned mapper tasks, some shuffle the data from mappers and hand it over to reducers, and some computers handle the reducer tasks. Between the mapper and reducer stages, a map-reduce system automatically reorganizes the intermediate key-value pairs, so that each call of the reducer function can receive a complete set of key-value pairs for a particular key, and so that the reducer function is called for every key in sorted order. We will refer to this reorganization of key-value pairs between the mapper and reducer stages as shuffling. Figure 2 illustrates the three steps of mapping, shuffling, and reducing.
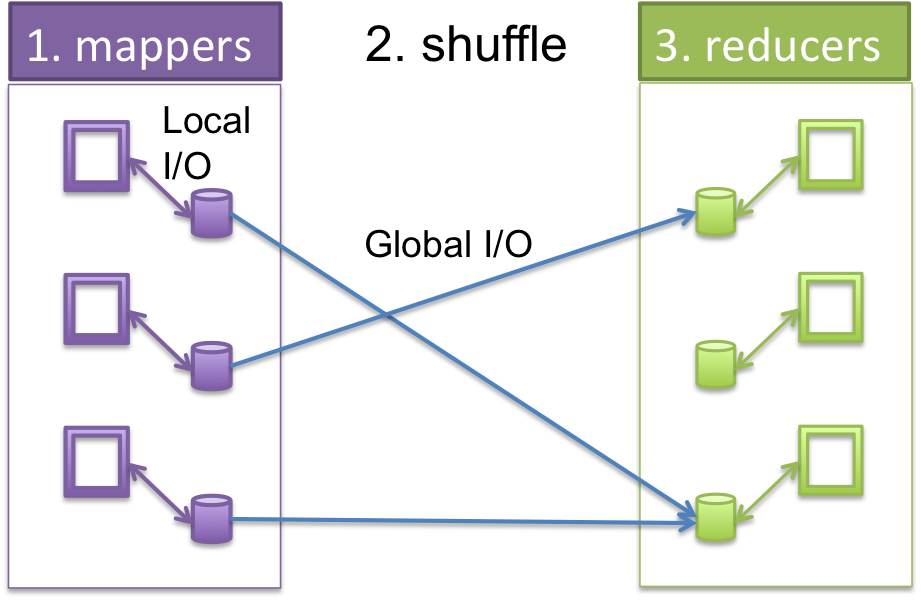
Figure 2: How each computer in a cluster breaks up the work and runs mappers locally, then shuffles the key-value pair results by key and sends the results for each key to other computers who run reducers.
Before the mapper stage, a map-reduce system such as Hadoop breaks the entire input data up into portions, known as splits; each split is assigned to one computer in a cluster, which then applies the mapper function to each line of that split. Thus,multiple computers can process different splits of data simultaneously. (With, say, 2000 computers or nodes in a large-scale commercial cluster, quadrillions of bytes (petabytes) of data might be processed in a few hours that might otherwise require years of computing time on a single computer.) Likewise, reducers may be run on multiple computers in order to speed up the performance of that stage.
Parallel computing is the practice of using multiple computations at the same time in order to improve the performance of those computations. The map-reduce programming model is an example of two varieties of parallel computing:
- Data parallelism, in which multiple portions of data are processed simultaneously on multiple processors (CPUs). This occurs when multiple splits of data are handled on different computers in a cluster.
- Pipelining, in which data is processed in a sequence of stages, like an assembly line. The mapper and reducer stages represent a two-stage pipeline. If shuffling is considered as its own stage, the pipeline would have three stages. Pipelining is an example of task parallelism, in which different computational tasks take place at the same time. In the case of the map-reduce stages, mapping could overlap with shuffling to some extent, by having mappers stream their output to shuffle processes, which would prepare it for reducers while the mappers are generating results. Thus, different computers could handle each of these tasks.
Note
Hadoop actually carries out the three stages of mapping, shuffling, and reducing sequentially (one stage after the other), instead of using task parallelism. That is, all of the mapping occurs before any of the shuffling begins, and all of the shuffling is completed before any of the reducing begins. (See below for reasons why.) Thus, Hadoop’s implementation of map-reduce doesn’t literally qualify as pipeline parallelism, because multiple stages do not take place at the same time. However, true pipeline parallelism does take place within our testing program used in the WebMapReduce interface, called wmrtest, which is useful for testing and debugging mapper and reducer functions with small data. In general, solving problems using pipeline (assembly line) thinking creates opportunities for using parallelism to improve performance.
Fault tolerance. Large (e.g., 2000-node) clusters offer the potential for great performance speedup, but breakdowns are inevitable when using so many computers. In order to avoid losing the results of enormous computations because of breakdowns, map-reduce systems such as Hadoop are fault tolerant, i.e., designed to recover from a significant amount of computer failure. Here are some fault-tolerance strategies used in Hadoop:
- All data is replicated on multiple computers. Thus,if one computer fails, its data is readily available on other computers.
- If a computer running a mapper function fails, that mapper operation can thus be restarted on another computer that has the same data (after discarding the partial results (key-value pairs) from incomplete mapper calls on that failed computer).
- If all mappers have completed, but a computer fails during shuffling, then any lost mapper results can be regenerated on another computer, and shuffling can resume using non-failed computers.
- Shuffling results are also replicated, so if a computer running reducers fails, those reducers can be rerun on another computer.
Note
Hadoop’s fault tolerance features make it a good use for the selkie cluster at Macalester, which uses the many computers in two large labs in the MSCS Department in Olin-Rice. Occasionally, these are sometimes unfortunately rebooted by users. These occasional failures of machines in the cluster can be compensated for by Hadoop. However, when many of these computers are rebooted at about the same time, all of the copies of some data may become unavailable, leading to Hadoop failures.
