Introduction¶
What is GPU?¶
Graphics Processing Unit (GPU), is an electronic circuit that, through rapid memory manipulation and massive parallel data processing, accelerates the building of images intended for output to a display. Right now, GPUs are used in almost all customer end personal computers, game consoles, professional workstations and even the cell phone you are holding.
Before GPU was introduced, CPU did all the graphic processing tasks. In the early 1990s, computer manufactures began to include GPU into computer systems with the aim of accelerating common graphics routines. After two decades of development, GPUs eventually outpaced CPUs as they actually had more transistors, ran faster and were capable of doing parallel computation more efficiently. GPUs became so complex that they are basically computers in themselves, with their own memory, buses and processors. Therefore, sometimes GPU is like an extra brain (supplemental processors) to the computer system. As GPU harnessed more and more horsepower, GPU manufactures, such as NVIDIA and ATI/AMD, found a way to use GPUs for more general purposes, not just for graphics or videos. This gave birth to CUDA structure and CUDA C Programming Language, NVIDIA’s response on facilitating the development of General Purpose Graphics Processing Unit (GPGPU).
What is the difference between GPU and CPU?¶
The major difference between GPU and CPU is that GPU has a highly parallel structure which makes it more effective than CPU if used on data that can be partitioned and processed in parallel. To be more specific, GPU is highly optimized to perform advanced calculations such as floating-point arithmetic, matrix arithmetic and so on.
The reason behind the difference of computation capability between CPU and GPU is that GPU is specialized for compute-intensive and highly parallel computations, which is exactly what you need to render graphics. The design of GPU is more of data processing than data caching and flow control. If a problem can be processed in parallel, it usually means two things: first, same problem is executed for each element, which requires less sophisticated flow control; second, dataset is massive and problem has high arithmetic intensity, which reduces the need for low latency memory.
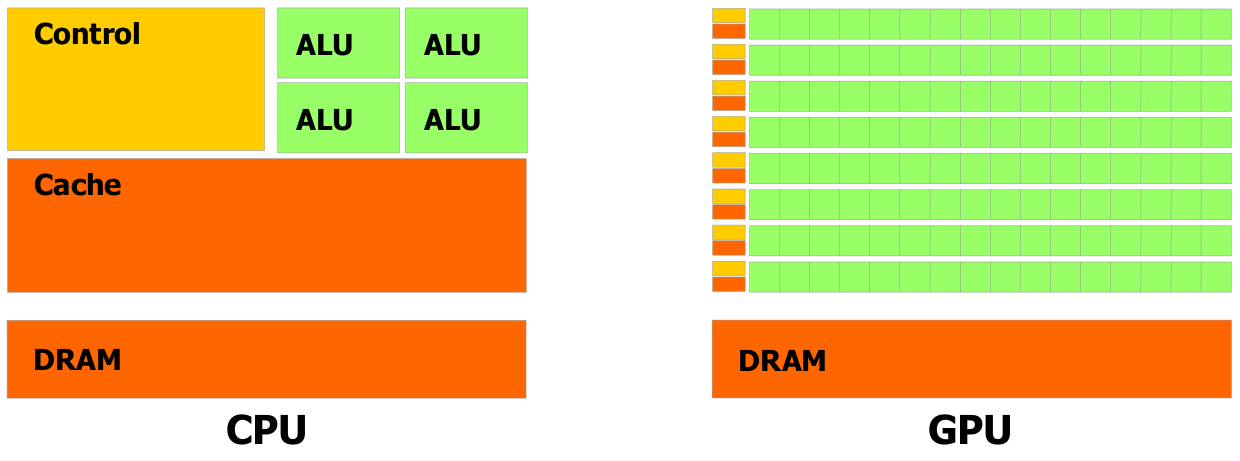
This figure is from the NVIDIA CUDA Programming Guide
The graph above shows the differences between CPU and GPU in their structure. Cache is designed for data caching; Control is designed for flow control; ALU (Arithmetic Logic Unit) is designed for data processing.
In the NVISION 08 Conference organized by the NVIDIA corporation, employers from NVIDIA used a rather interesting yet straight forward example illustrating the difference between CPU and GPU. You can watch the video by clicking the link below and hope it can give you a better idea about what the difference between GPU and CPU is. Video
What is the advantage of using GPU for computation?¶
Nowadays, most of the scientific researches require massive data processing. What scientist usually do right now is to have all the data being processed on supercomputing clusters. Although most universities have constructed their own parallel computing clusters, researchers still need to compete for time to use the shared resources that not only cost millions to build and maintain, but also consume hundreds of kilowatts of power.
Different from traditional supercomputers that are built with many CPU cores, supercomputers with a GPU structure can achieve same level of performance with less cost and lower power consumption. Personal Supercomputer (PSC) based on NVIDIA’s Tesla companion processors, was first introduced in 2008. The first generation four-GPU Tesla personal supercomputer have 4 Teraflops of parallel supercomputing performance, more than enough for most small researches. All it takes is 4 Tesla C1060 GPUs with 960 cores and two Intel Xeon processors. Moreover, Personal supercomputer is also very energy efficient as it can even run off a 110 volt wall circuit. Although supercomputer with GPUs cannot match the performance of the top ranking supercomputers that cost millions even billions, it is more than enough for researchers to perform daily research related computations in subjects like bioscience, life science, physics and geology.
What are the important parts inside a GPU?¶
Although modern GPUs are basically computers themselves, they still serve as a part of a computer system. A modern GPU is connected with the host through a high speed I/O bus slot, usually a PCI-Express slot. Modern GPUs are extremely energy consuming. Some of the GPUs alone consume hundreds watts of power, sometimes higher than all other parts of the computer system combined. Part of the reason that GPUs require such power supply is that they have much complex structure and can perform much sophisticated task than other parts of computer system. Owe to its high capability, GPU needs its own memory, control chipset as well as many processors.
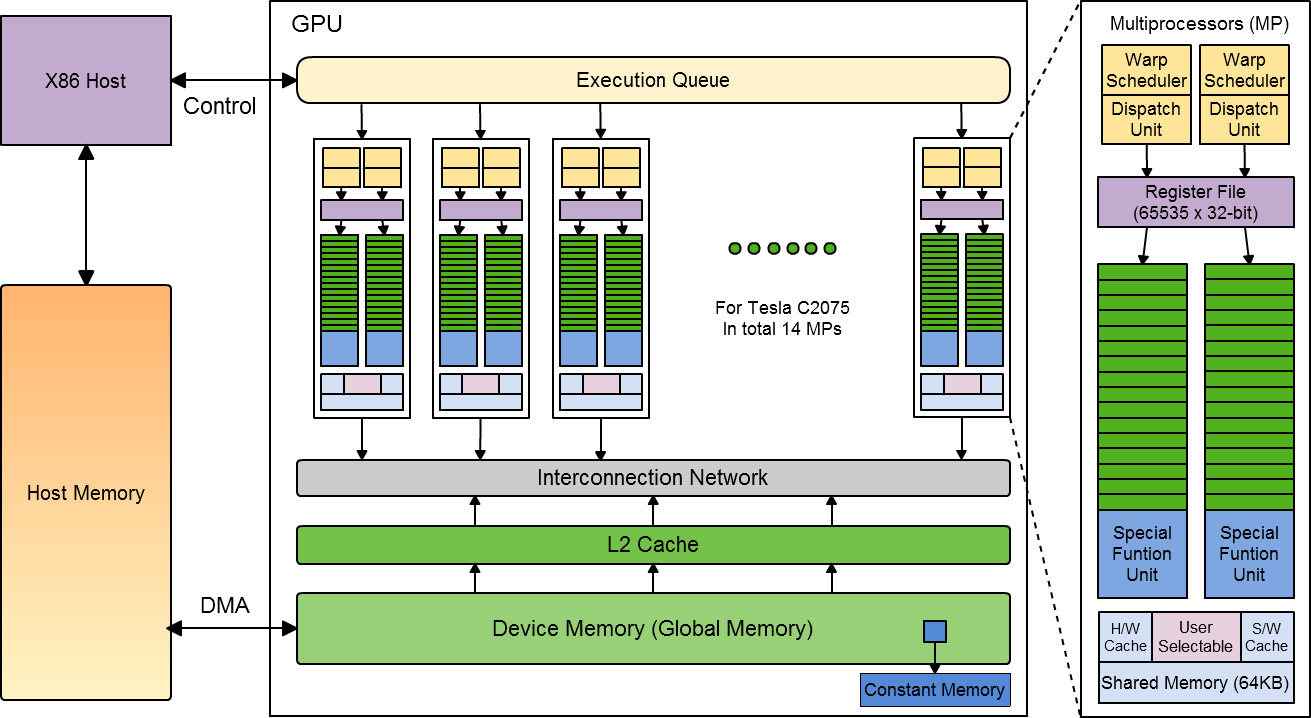
This figure is inspired by the figure found in Understanding the CUDA Data Parallel Threading Model: A Primer written by Michael Wolfe from The Portland Group
GPUs these days are usually equipped with several gigabytes of on-board memory for user configuration. GPUs designed for daily use like gaming and video rendering, such as NVIDIA’s Geforce series GPUs and ATI/AMD’s Radeon series GPUs, have on-board memory capacity ranging from several hundreds megabytes to several gigabytes. Professional GPUs designed for high-definition image processing and General Purpose Computation, such as the Tesla Companion Processor we are using, usually have memory up to 5 or 6 gigabytes. Data are transferred between the GPU on-board memory and host memory through a method called DMA (Direct Memory Access). One thing worth mentioning is that CUDA C programming language supports direct access of the host memory from GPU end under certain restrictions. As GPU is designed for compute-intensive operations, device memory usually supports high data bandwidth with not deeply cached memory hierarchy.
GPUs from NVIDIA have many processors, called streaming Processors (SP). Each streaming processor is capable of executing a sequential thread. For a GPU with Fermi architecture, like the one we are using, every 32 streaming processors is organized in a Streaming Multiprocessor (SM). A GPU can have one or more multiprocessors on board. For example, the Tesla C2075 GPU card we are using, has 14 multiprocessors built in. Except for 32 streaming processors, each multiprocessor is also equipped with 2 warp scheduler, 2 special function units (4 in some GPUs), a set of 32-bit registers and 64KB of configurable shared memory. A warp scheduler is responsible for threads control; SFU handles transcendentals and double-precision operations. For a GPU with Kepler architecture, every 192 streaming processor is organized in a multiprocessor. There are also more warp schedulers and SFUs built in.
Shared memory, or L1 cache, is a small data cache that can be configured through software. Shared memory is also shared among all the streaming processors within one multiprocessor. Compared with on-board memory, shared memory is low-latency (usually register speed) and has high bandwidth. Each multiprocessor has 64KB of shared memory that can be configured by using special commands in host code. Shared memory is distributed to software-managed data cache and hardware data cache. The user can choose to assign either 48KB to software-managed data cache (SW) and 16KB to hardware data cache (HW) or the other way around.
How does CUDA connect with hardware?¶
When the host code invokes a kernel grid through a CUDA program, blocks in the grid are distributed to different multiprocessors based on available execution capacity of each multiprocessor. Each multiprocessor is capable of processing one or more blocks throughout the kernel execution. However, each block can only be processed by one multiprocessor.
Fermi architecture supports up to 48 active warps on each multiprocessor. The advantage of having many active warps in a process at the same time is significant reduction of memory latency. Traditionally, memory latency is reduced by adding more cache memory hierarchy into the system. However, by using high degree of multithreading, GPUs can also effectively reduce memory latency. What happens is that when one warp stalls on memory operation, the multiprocessor can select another warp and begin to process that one.
When a block is processed by a multiprocessor, threads in this block are further divided into groups of 32 threads, what NVIDIA calls a warp. Although 32 streaming processors in a block and 32 threads in a warp seems to be a good match for each multiprocessor to process each warp in one clock cycle, the reality is somehow different. As mentioned previously, each multiprocessor has two warp schedulers, which enables it to process two warps simultaneously. After the partition, each warp gets scheduled by a warp scheduler for execution. Each warp scheduler pumps 16 threads (half warp) into a group of 16 streaming processors for execution. Therefore, it would take two clock cycles to process each warp and one multiprocessor can process two warps in two clock cycles. For double-precision operations, each multiprocessor would combine two groups of streaming processors so that they act as a multiprocessor with 16 double-precision streaming processors.
Is CUDA the only GPU programming language available?¶
When we are learning CUDA C programming language, it is important for you to know that the C programming language is not the only language that can be bound with CUDA structure. NVIDIA also made other programming languages available such as Fortran, Java and Python as binding languages with CUDA.
Furthermore, NVIDIA is not the only company manufacturing GPU cards, which means CUDA is not the only GPU programming MPI available. When NVIDIA were developing CUDA, AMD/ATI responded with ATI Stream, their GPGPU technology for AMD/ATI Radeon series GPUs. ATI Stream technology uses OpenCL as its binding language.
