A Single-process Web Crawler, or Spider¶
The World Wide web is aptly named when you consider the URL links found in pages. One page can have many links in it that take a viewer to another page, which has more links, and so on, forming a very large cyclic graph of interconnected pages.
In this lab you will be finishing some code for a web crawler, or spider, that will start with a ‘seed’ URL to a web page and read it to find links to other pages. Those links will be placed on a queue for further processing (we’ll call this the work queue). When the initial page is processed, it is placed on another data structure to indicate that it has been visited already– this is the finished queue. This process is repeated for the next page whose link is on the work queue.
The code you will be given uses a Java library for parsing html files and looking for links (java.net.URL).
To Start With¶
Here are the files in the package lab.spider, which you will use as your starting point. Place these files into your Java IDE as indicated by your instructor.
AllWordsCounter.java // contains a ‘dictionary’ to hold counts of how often a URL is encounterd
HttpHelper.java // contains methods to read html pages and extract links; also can detect whether a URL is an image
RunSpider.java // has main()
Spider.java // the workhorse and the one you will be changing
TestHttpHelper.java // JUnit test class
TestSpider.java // JUnit test class
WordCount.java // small helper class that holds a word and a count
The Spider.java class is the one that you should work on for this assignment. The RunSpider class contains main() and uses it. As the code stands now it doesn’t really do anything if you run it.
Examine the code in the files. Begin by creating a class diagram that shows which classes ‘use’ or ‘have’ one of the other classes.
Java Collection Data Structures Used¶
Become familiar with the data structures that are used in this program. The diagram below illustrates them.
The class called AllWordsCounter is able to return an array of WordCount objects, each of which contains two data elements: a URL for a page, and a count of the number of times that URL was encountered by the crawler. In the Spider class, the method getUrlCounts will return this array, shown on the left in the picture below. This array can be used to examine what the spider encountered when it is finished running.
The Spider class also contains a Queue called work and a List called finished. The Spider will start at a given, predetermined page and read all the links to URLs on it (this is called scraping the page, which you will implement in the processPage method). The links it finds, illustrated on the far upper right in the following diagram, should be added to the work queue, and a counter for that link should be updated.
The Spider class will repeat this process in the crawl method by continuing to pull each URL to a page off the work queue, process it, and place it in the finished queue. This is done for a certain number of times as designated by the integer called maxUrls.
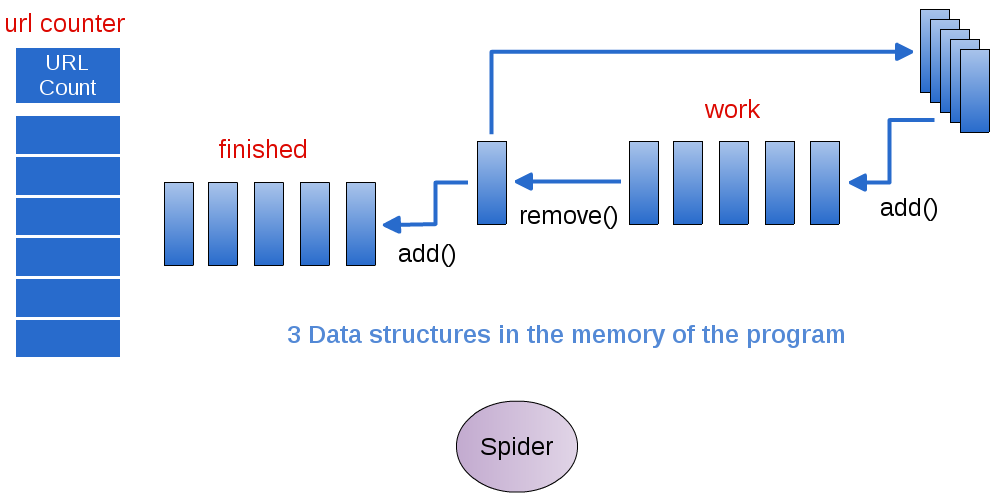
Single Spider accesses the data and does all the work
To Do¶
Your task is to finish the Spider class by doing the following:
- Complete the processPage method. When it works, one of the TestSpider unit tests should pass.
- Complete the crawl() method. When it works, both TestSpider unit tests should pass.
Note
There are comments in these methods to help assist you.
Once your unit tests pass, you should be able to run the code by executing the main method of the RunSpider class, which is currently ‘hard-coded’ to start at macalester.edu, and see it produce the URLs found when crawling, along with how many times it saw them.
Try This:
- Experiment with this variable found in Spider: maxurls If you double it, how many new urls were encountered? You might want to make a method that would answer this for you.
- Experiment with the BEGNNING_URL variable found in RunSpider by choosing some other pages of interest to you as starting points.
